Sumário
- 1 - Resumo
- 2 - Introdução
- 3 - Teoria: Baseando-nos no Conhecimento para Combater o Mal
- 3.1 - URLs: Navegando na Web com Segurança
- 3.2 - Aprendizado de Máquina: Inteligência Artificial para o Bem
- 3.3 - Classificação: Separando o Bom do Mau
- 3.4 - Hiperparâmetros: Ajustando o Modelo para o Sucesso
- 3.5 - Revisão de Estudos Anteriores: Aprendendo com o Passado
- 3.6 - Localizadores Uniformes de Recursos: Navegando na Web com Precisão
- 3.7 - Aprendizado de Máquina: Treinando Modelos Inteligentes
- 3.8 - Aprendizado de Máquina: A Base da Detecção de URLs Maliciosas
- 3.9 - Pesquisas anteriores
- 4 - Processo e resultados
- 4.1 - Metodologia
- 4.2 - Mergulhando na Coleta de Dados: A Base para Detecção Precisa de URLs Maliciosos
- 4.2.1 - Fonte de Dados: Kaggle - Um Tesouro de URLs
- 4.2.2 - Desafios e Oportunidades: Lidando com Dados Desequilibrados
- 4.2.3 - Gerando Conjuntos de Dados: Diversidade para Treinamento Robusto
- 4.2.4 - Engenharia de recursos
- 4.2.5 - Modelos
- 4.2.6 - Árvore de Decisão: Desvendando a Simplicidade e a Eficiência
- 4.3 - Resultados: Desvendando o Desempenho dos Modelos
- 4.3.1 - Ajuste de Hiperparâmetros: A Busca pela Perfeição
- 4.3.2 - Validação Cruzada K-fold: Equilíbrio Entre Precisão e Eficiência
- 4.3.3 - Hiperparâmetros sob Análise: Uma Visão Detalhada
- 4.3.4 - Conjunto de dados de teste
- 4.3.5 - Conjunto de Dados Aleatório: Desequilíbrio e Desafios
- 4.3.6 - Conjunto de Dados DRLSH: Diversidade e Desafios
- 4.3.7 - Conjunto de Dados BPLSH: Ambiguidade e Desafios
- 4.3.8 - Um Elemento Crucial na Detecção de URLs Maliciosos
- 4.4 - Discussão: Limitações dos Métodos BPLSH e DRLSH para Redução de Conjuntos Desequilibrados
- 5 - Conclusão
- 6 - Referências
1. Resumo
Diariamente, milhões de novos sites são criados, o que complica a identificação dos que são seguros. A cibersegurança é essencial para proteger empresas e usuários de ataques online. Cibercriminosos utilizam várias técnicas, como phishing, para enganar usuários a divulgar dados pessoais. Em 2022, só na Austrália, foram reportados mais de 74.000 ataques de phishing, causando perdas financeiras superiores a 24 milhões de dólares. A inteligência artificial e o aprendizado de máquina são utilizados em várias áreas, desde a detecção de câncer até o combate a fraudes financeiras e desenvolvimento de chatbots. Modelos de aprendizado de máquina, como Random Forest e Support Vector Machines, são amplamente empregados em tarefas de classificação. Com o aumento da criminalidade cibernética, é vital empregar essas tecnologias para detectar URLs maliciosas, tanto novas quanto conhecidas. O foco deste estudo é avaliar diferentes técnicas de seleção de instâncias e modelos de aprendizado de máquina para classificar URLs maliciosas.
Para este estudo, foi usado um conjunto de dados do Kaggle contendo cerca de 650.000 URLs, dividido em quatro categorias: phishing, desfiguração, malware e benignas. Foram criados três subconjuntos de dados, cada um com aproximadamente 170.000 URLs, utilizando diferentes técnicas de seleção de instâncias (DRLSH, BPLSH e seleção aleatória) implementadas no MATLAB. Vários modelos de aprendizado de máquina, incluindo SVM, DT, KNNs e RF, foram testados. Esses modelos foram treinados com os conjuntos de dados selecionados e avaliados com base em 16 características e um alvo de classificação. Durante o ajuste de hiperparâmetros, foi usada otimização bayesiana para determinar os melhores hiperparâmetros para cada modelo. Após a classificação, os resultados foram comparados, revelando que a seleção aleatória de instâncias superou as técnicas DRLSH e BPLSH em precisão e tempo de processamento. A menor precisão dos métodos DRLSH e BPLSH pode ser atribuída ao desequilíbrio dos conjuntos de dados, que resultou em uma seleção de amostra inadequada.
Palavras-chave: Aprendizado de máquina, segurança cibernética, classificação, URL malicioso, ataques de phishing
2. Introdução
A internet se expande a cada dia, com milhões de novos sites surgindo e coletando dados de usuários através de logins e outras funções. Essa vastidão torna desafiador discernir quais plataformas são realmente seguras e confiáveis [1]. É nesse contexto que a segurança cibernética se ergue como um conjunto vital de ferramentas e técnicas para proteger empresas e indivíduos contra ataques cibernéticos [2, p. 2].
No entanto, os cibercriminosos são perspicazes e exploram diversas maneiras de manipular usuários online para obter informações confidenciais e pessoais. Uma tática comum é o uso de URLs maliciosos, disfarçados como hiperlinks legítimos. Ao interagir com esses links, os usuários se colocam em risco, desde o comprometimento de dados sensíveis até se tornarem alvos principais de ataques cibernéticos. A Comissão Australiana de Concorrência e Consumidores, por exemplo, registrou um total de 74.567 casos de ataques de phishing na Austrália em 2022, resultando em um prejuízo financeiro superior a 24 milhões de dólares [3].
2.1. Inteligência Artificial: Uma Mente Robótica em Ação
A inteligência artificial (IA) se destaca como a arte da computação, concedendo às máquinas a capacidade de realizar tarefas específicas sem a necessidade de instruções explícitas. Essa tecnologia revolucionária visa imitar o cérebro humano, alcançando um nível de inteligência similar ao nosso. A IA já provou sua eficácia em diversas áreas [4], como :
- Diagnóstico médico preciso: A IA supera os médicos na detecção e no diagnóstico de tecidos cancerígenos, salvando vidas com maior rapidez e precisão.
- Combate ao crime financeiro: A IA atua como um vigilante digital, identificando esquemas criminosos em transações financeiras, protegendo o sistema bancário e seus usuários.
- Chatbots inteligentes: Assistentes virtuais que simulam conversas naturais, respondendo perguntas e oferecendo suporte aos usuários de forma eficiente e amigável.
2.1.1. Aprendizado de Máquina: Desvendando os Segredos dos Dados
O aprendizado de máquina, um ramo da IA, capacita sistemas computacionais a aprender e identificar padrões, estruturas e categorias a partir de grandes volumes de dados. Essa tecnologia utiliza métodos estatísticos e algoritmos avançados para desvendar os segredos dos dados, dividindo-se em dois tipos principais:
- Aprendizagem supervisionada: Nesse modelo, os dados são pré-definidos, fornecendo tanto as entradas quanto os resultados desejados para o modelo aprender.
- Aprendizagem não supervisionada: Aqui, o modelo explora os dados sem a necessidade de um conjunto pré-definido, buscando padrões e insights por conta própria. [5, p. 429].
O aprendizado profundo, um subconjunto do aprendizado de máquina, imita a estrutura do cérebro humano, utilizando múltiplas camadas para processar informações de forma complexa e eficiente. Entre os modelos de aprendizado de máquina mais conhecidos [6] e eficazes, podemos destacar:
- Random Forest (RF)
- Support Vector Machine (SVM)
- Árvore de Decisão (DT)
- Regressão Logística (LR)
- K-vizinhos mais próximos (KNNs)
- Naive Bayes (NB)
Esses modelos são ferramentas valiosas na classificação de dados, utilizados em diversas áreas como análise de dados, marketing, medicina e finanças.
2.2. Descrição do Problema: Ameaças Digitais à Espreita
A internet se tornou uma ferramenta essencial em nossas vidas, mas com ela surgiram novas formas de crime: os crimes cibernéticos. Esses ataques visam violar nossa privacidade, utilizando computadores para acessar informações confidenciais e sensíveis.
O phishing, uma técnica comum, envolve o envio de emails ou mensagens fraudulentas para enganar os usuários a revelar dados pessoais, como senhas ou informações bancárias. As consequências podem ser graves, incluindo roubo de identidade, perda financeira e até mesmo danos à reputação [7].
Outro método utilizado pelos criminosos é o defacement, onde invadem sites e alteram seu conteúdo, muitas vezes para fins propagandísticos ou para prejudicar a imagem da organização. Em 2014, de acordo com o relatório da RSA, quase 450 mil sites de phishing causaram um prejuízo de US$ 5,9 bilhões [9].
Para combater esses crimes, listas negras com URLs maliciosos conhecidos são utilizadas. No entanto, essa abordagem não é totalmente eficaz, pois novos sites maliciosos surgem constantemente. É aí que o aprendizado de máquina entra em cena [10].
2.3. 1.3. Objetivo: Uma Arma Inteligente contra o Crime Cibernético
O objetivo deste estudo é investigar e comparar o desempenho de diferentes métodos de seleção de instâncias e modelos de aprendizado de máquina na classificação de URLs maliciosos. Através dessa pesquisa, buscamos responder às seguintes perguntas:
- Quais características dos URLs são mais importantes para a sua classificação como maliciosos ou não?
- Quais modelos de aprendizado de máquina e métodos de seleção de instâncias são mais eficientes na classificação de URLs maliciosos?
3. Teoria: Baseando-nos no Conhecimento para Combater o Mal
Nesta seção, aprofundaremos nosso conhecimento sobre URLs, aprendizado de máquina, classificação e hiperparâmetros. Também revisaremos pesquisas anteriores sobre a aplicação do aprendizado de máquina na identificação de URLs maliciosos.
Através da combinação de teoria e prática, esperamos desenvolver um modelo de aprendizado de máquina robusto e eficaz para auxiliar na luta contra os crimes cibernéticos, protegendo os usuários e suas informações na era digital.
3.1. URLs: Navegando na Web com Segurança
Um URL (Uniform Resource Locator) é o endereço de um site na internet. É a forma como encontramos e acessamos páginas na web. Ao analisarmos os URLs, podemos identificar características que podem indicar se um site é malicioso ou não, como a presença de palavras-chave suspeitas ou a origem do URL.
3.2. Aprendizado de Máquina: Inteligência Artificial para o Bem
O aprendizado de máquina é um ramo da inteligência artificial que permite que os computadores aprendam a partir de dados. Através de algoritmos complexos, os modelos de aprendizado de máquina podem identificar padrões e fazer previsões, sem a necessidade de serem explicitamente programados.
3.3. Classificação: Separando o Bom do Mau
A classificação é uma tarefa de aprendizado de máquina que visa categorizar dados em diferentes classes. No nosso caso, a classificação de URLs maliciosos envolve a identificação de URLs que representam um risco à segurança dos usuários.
3.4. Hiperparâmetros: Ajustando o Modelo para o Sucesso
Os hiperparâmetros são configurações que controlam o funcionamento dos modelos de aprendizado de máquina. A escolha adequada dos hiperparâmetros é crucial para o bom desempenho do modelo na tarefa de classificação de URLs maliciosos.
3.5. Revisão de Estudos Anteriores: Aprendendo com o Passado
Ao revisar pesquisas anteriores sobre a aplicação do aprendizado de máquina na identificação de URLs maliciosos, podemos aprender com as experiências e resultados de outros pesquisadores. Isso nos permitirá desenvolver um modelo mais robusto e eficaz, aprimorando a luta contra os crimes cibernéticos.
3.6. Localizadores Uniformes de Recursos: Navegando na Web com Precisão
Um URL (Uniform Resource Locator), também conhecido como endereço da web, é o código único que identifica um recurso específico na internet, como uma página HTML, imagem ou vídeo. Ao inserir um URL em um navegador, você é direcionado diretamente para o conteúdo desejado.
3.6.1. Analisando a Estrutura de um URL:
Um URL completo é composto por diversas partes, cada uma com uma função específica:
- Protocolo: Define o método de comunicação com o servidor, sendo os mais comuns HTTPS (conexão segura e criptografada) e HTTP (conexão não criptografada).
- Endereço IP: Identifica o servidor web que armazena o conteúdo desejado.
- Porta: Indica o canal de comunicação específico a ser usado para acessar o conteúdo. A porta padrão para HTTP é 80 e para HTTPS é 443.
- Caminho: Especifica o local exato do recurso dentro do servidor web, como pastas e subpastas.
- Parâmetros: Permitem enviar informações adicionais para o servidor, geralmente na forma de pares chave-valor.
- Âncora: Direciona o usuário para uma seção específica dentro da página web, indicada por um identificador (#).
Observações Importantes:
- Parâmetros e âncoras nem sempre são necessários e podem ser omitidos do URL.
- A estrutura de um URL pode variar de acordo com o tipo de recurso e o servidor web utilizado [11].


3.7. Aprendizado de Máquina: Treinando Modelos Inteligentes
O aprendizado de máquina é um campo da inteligência artificial que permite que computadores aprendam a partir de dados, sem a necessidade de serem explicitamente programados. Nele, algoritmos complexos identificam padrões e fazem previsões, tornando-se ferramentas valiosas para diversas tarefas [12, p. 1310].
3.7.1. Classificação: Separando o Bom do Mau
Na classificação, um tipo de aprendizado de máquina supervisionado, o objetivo é categorizar dados em diferentes classes, com base em exemplos previamente rotulados. No contexto da classificação de URLs maliciosos, o algoritmo é treinado com um conjunto de URLs já classificados como maliciosos ou benignos, aprendendo a identificar as características que distinguem cada categoria.
O Processo de Classificação em Etapas:
- Preparação:
- Seleção de Dados: Um conjunto de dados adequado e abrangente é crucial para o treinamento do modelo.
- Limpeza de Dados: Remover valores ausentes e inconsistentes garante a qualidade dos dados.
- Extração de Recursos: Identificar as características relevantes dos URLs é essencial para a classificação precisa.
- Aprendizagem:
- Desenvolvimento do Modelo: O algoritmo de classificação aprende com os dados de treinamento, estabelecendo relações entre as características e as classes.
- Avaliação:
- Teste do Modelo: O modelo é avaliado com um conjunto de dados de teste não utilizado no treinamento, medindo seu desempenho em novos dados.
3.7.2. Hiperparâmetros: Ajustando o Modelo para o Sucesso
Os hiperparâmetros são configurações que controlam o funcionamento dos modelos de aprendizado de máquina. Ajustá-los de forma adequada é crucial para otimizar o desempenho do modelo e alcançar a melhor precisão possível.
Otimização de Hiperparâmetros: Refinando o Modelo
- Treinamento, Validação e Teste: O processo de otimização envolve dividir os dados em conjuntos para treinamento, validação e teste.
- Evitar Overfitting: O overfitting ocorre quando o modelo se concentra excessivamente nos dados de treinamento, perdendo a capacidade de generalizar para novos dados. Técnicas como validação cruzada e regularização ajudam a prevenir esse problema.
3.8. Aprendizado de Máquina: A Base da Detecção de URLs Maliciosas
O aprendizado de máquina se tornou uma ferramenta crucial na luta contra URLs maliciosas. Entre as técnicas de aprendizado de máquina, a classificação se destaca como a mais utilizada para essa tarefa. [12, p. 1310].
3.8.1. Classificação
A classificação é um método de aprendizado supervisionado que consiste em categorizar dados com base em informações adquiridas durante o treinamento. Esse treinamento envolve o uso de um conjunto de dados pré-classificado para ensinar o algoritmo a reconhecer padrões e categorias. A fase de classificação é crucial para a capacidade do modelo de organizar corretamente os dados conforme suas características [13, 14].
Durante a preparação, é fundamental garantir que o modelo de classificação receba o treinamento adequado, selecionando e preparando o conjunto de dados corretamente, removendo dados incompletos e destacando características relevantes. Após o treinamento, o modelo é desenvolvido para reconhecer categorias com base nas características dos dados. Na etapa de avaliação, testa-se o modelo com um conjunto de dados novo, distinto do utilizado no treinamento, para verificar sua eficácia em condições reais [14].
3.8.2. Hiperparâmetros
Hiperparâmetros são variáveis que configuram o processo de treinamento do modelo de aprendizado de máquina e podem influenciar significativamente o seu desempenho. Ajustar esses parâmetros pode melhorar a precisão e eficiência do modelo. A otimização de hiperparâmetros busca encontrar a combinação ideal que maximize o desempenho do modelo em novos dados, evitando problemas como overfitting, que ocorre quando um modelo se ajusta demasiadamente ao conjunto de treinamento a ponto de perder a capacidade de generalizar para novos dados. Estratégias diversas são aplicadas para mitigar o overfitting e aprimorar a capacidade do modelo de funcionar bem em situações reais [15, 16].
Otimização de Hiperparâmetros: Refinando o Modelo
Treinamento, Validação e Teste: O processo de otimização envolve dividir os dados em conjuntos para treinamento, validação e teste.
Evitar Overfitting: O overfitting ocorre quando o modelo se concentra excessivamente nos dados de treinamento, perdendo a capacidade de generalizar para novos dados. Técnicas como validação cruzada e regularização ajudam a prevenir esse problema.

Os dados de treinamento servem para educar o modelo. Por outro lado, os dados de validação, que são distintos dos de treinamento, têm como função principal avaliar a eficácia do modelo. Após as etapas de treinamento e validação, utiliza-se um conjunto de dados de teste para verificar como o modelo se comporta com dados completamente novos [17].
No mundo do aprendizado de máquina, encontrar a configuração ideal para um modelo pode ser como procurar uma agulha em um palheiro. É aí que a otimização bayesiana entra em cena, oferecendo uma solução elegante e eficiente para este desafio.
O Que é Otimização Bayesiana?
A otimização bayesiana é como um explorador experiente, navegando pelo terreno acidentado das configurações de modelo em busca do "ponto ideal". Ela utiliza um modelo substituto, um mapa preliminar construído a partir de pontos que representam diferentes combinações de hiperparâmetros para o modelo.
Como Funciona a Otimização Bayesiana?
A otimização bayesiana segue um processo iterativo inteligente:
Seleção do Próximo Ponto: O explorador bayesiano utiliza o modelo substituto para identificar o próximo ponto que promete o maior "tesouro" - ou seja, a maior melhoria na função objetivo, f(x). Essa função representa o que queremos otimizar, seja a precisão do modelo ou a eficiência computacional.
Avaliação do Ponto Selecionado: O explorador então "cava" no ponto selecionado, avaliando a função objetivo f(x) nesse ponto. Essa avaliação fornece informações valiosas sobre o terreno local.
Atualização do Mapa: Com base na nova avaliação, o explorador atualiza o modelo substituto, aprimorando seu conhecimento sobre o "terreno" das configurações de modelo.
Medindo a Melhoria: Encontrando o Caminho Certo
Para guiar sua jornada, a otimização bayesiana utiliza diferentes métricas para medir a "melhoria" prometida em cada ponto:
1 M. Aslani,” Introdução às Redes Neurais”, Apresentação, Universidade de Gävle, 6 de março de 2023.
Melhoria Provável: A probabilidade de que a avaliação do próximo ponto resulte em uma melhoria significativa.
Melhoria Esperada: A quantia média de melhoria esperada no próximo ponto.
Limite de Confiança Inferior: O limite inferior da melhoria potencial no próximo ponto, garantindo um certo nível de confiança.
O Processo Gaussiano: O Mapa Essencial
O modelo substituto na otimização bayesiana geralmente é um processo gaussiano (GP), um mapa probabilístico que nos ajuda a entender e prever funções desconhecidas. Ele faz isso usando duas funções importantes:
Função Média: Esta função fornece uma estimativa inicial ou linha de base para a aparência da função desconhecida.
Função Kernel: Esta função captura a semelhança ou correlação entre diferentes pontos de dados, quantificando a probabilidade de pontos próximos terem valores semelhantes.
Ao combinar essas funções, o GP nos permite fazer previsões precisas e compreender o comportamento geral dos dados, tornando-o uma ferramenta essencial para a otimização bayesiana [18, pp. 30505, 30514].
3.9. Pesquisas anteriores
A batalha contra URLs maliciosos é um campo de pesquisa ativo, com diversos estudos explorando diferentes técnicas de aprendizado de máquina para identificar e classificar esses links nefastos. Nesta análise, vamos mergulhar em pesquisas relevantes, desvendando suas metodologias, conjuntos de dados e resultados.
- Mestrado Aljabri [19]: Uma Análise Abrangente com Precisão de 95%
- Conjunto de Dados: Mais de 1 milhão de URLs com atributos como IP, localização e HTTPS.
- Divisão: Treinamento (1,2 milhão) e Teste (0,364 milhão).
- Recursos: 12 características extraídas do conjunto de dados.
- Modelos: Naive Bayes (NB) e Random Forest (RF).
- Resultado: NB apresentou a maior precisão, com 95%.
- Y. Li [20]: SVM Destaca-se com Precisão de 94,45%
- Conjunto de Dados: Aproximadamente 52.000 URLs.
- Divisão: 70% para Treinamento e 30% para Teste.
- Recursos: 8 recursos, incluindo HTTPS, IP, pontos no nome de domínio e TLD.
- Modelos: SVM, KNN, DT, RF, Gradient Boost Decision Tree (GBDT), XGBoost (XGB) e LightGBM (LGB).
- Resultado: SVM liderou com precisão de 94,45%.
- Saleem Raja [21]: RF Impera com Precisão de 99%
- Conjunto de Dados: Aproximadamente 66.000 URLs.
- Divisão: 70% para Treinamento e 30% para Teste.
- Modelos: SVM, Logistic Regression (LR), KNN, NB e RF.
- Recursos: Cerca de 20 recursos, como comprimento de URL, HTTPS, dígitos, letras e símbolos.
- Resultado: RF atingiu a maior precisão (99%), seguido por SVM (98%).
- SH Ahmed [7]: LGB brilha com Precisão de 89,5%
- Conjunto de Dados: 3.000 URLs (1.500 maliciosos e 1.500 benignos).
- Objetivo: Desenvolver um modelo de aprendizado de máquina para detecção de URLs maliciosos.
- Modelos: RF, DT, LGB, LR e SVM.
- Divisão: 80% para Treinamento e 20% para Teste.
- Recursos: 15 recursos, incluindo nome de domínio, comprimento de URL e HTTPS.
- Resultado: LGB liderou com 89,5% no treinamento e 86% no teste. RF ficou em segundo (88,3% e 85,3%).
- Kaggle [22]: DT, RF e Trivial Trees com Precisão de 91%
- Conjunto de Dados: 428.103 URLs benignas, 96.457 de desfiguração, 94.111 de phishing e 32.520 de malware.
- Modelos: DT, RF, KNN, Novel Trees, Gaussian NB, Stochastic Gradient Descent e Ada-boost.
- Resultado: DT, RF e Trivial Trees alcançaram a maior precisão (91%).
- Patil [23]: RF Destaca-se com Precisão Superior a 91%
- Conjunto de Dados: 651.191 URLs (malware, desfiguração, benignas e phishing).
- Modelos: XGB, LGB e RF.
- Extração de Características: IP, letras, dígitos e caracteres não alfanuméricos.
- Resultado: RF liderou com precisão superior a 91%.
4. Processo e resultados
Nossa jornada na detecção de URLs maliciosos se inicia com a metodologia, a base fundamental para alcançar resultados precisos e confiáveis. Nesta seção, vamos desvendar os segredos do nosso processo, explorando cada etapa com minúcia.
4.1. Metodologia
O procedimento adotado envolveu três etapas principais (ver Figura 3). A primeira etapa foi a preparação de dados, na qual os dados relevantes foram selecionados e purificados para a análise. Essencial para o sucesso foi a qualidade dos dados usados para treinar o modelo, eliminando-se valores nulos que pudessem afetar negativamente o treinamento. Verificações confirmaram a ausência de valores nulos, garantindo que não faltassem categorias para URLs ou outras informações. Neste ponto, características previamente identificadas por estudos anteriores para reconhecer URLs maliciosas foram selecionadas para inclusão no dataset. O estudo destinou 85% dos dados para treinamento e 15% para testes.
Os modelos foram treinados com o conjunto de treinamento para ajustar e otimizar hiperparâmetros usando otimização bayesiana. Esses hiperparâmetros ajustados foram aplicados em conjuntos reduzidos durante o treinamento subsequente. Foram criados três conjuntos de dados por meio de diferentes métodos de seleção de instâncias, visando acelerar o treinamento e os testes.
A segunda etapa envolveu o desenvolvimento de modelos capazes de categorizar os dados com base em suas características. A etapa final foi a avaliação, onde os modelos foram testados com novos dados que não foram utilizados no treinamento. Para minimizar o risco de superajuste, aplicou-se a validação cruzada K-fold, dividindo o dataset em várias subconjuntos. Neste estudo, foram realizadas cinco iterações de validação cruzada usando o software MATLAB, que dividiu os dados em cinco partes em cada iteração. Por exemplo, na primeira iteração, as dobras de 2 a 5 serviram como treinamento, enquanto a dobra 1 foi usada para testes. Este processo foi repetido até que todas as dobras fossem usadas como teste, garantindo uma avaliação robusta da capacidade de generalização do modelo em diferentes subconjuntos de dados.

4.2. Mergulhando na Coleta de Dados: A Base para Detecção Precisa de URLs Maliciosos
4.2.1. Fonte de Dados: Kaggle - Um Tesouro de URLs
Nossa jornada na detecção de URLs maliciosos começa com a coleta de dados, a base fundamental para treinar e avaliar nossos modelos de aprendizado de máquina. Para isso, utilizamos um conjunto de dados existente da plataforma Kaggle [25], um repositório rico em informações valiosas.
Este conjunto de dados, com cerca de 650.000 URLs, representa uma mina de ouro para nossa missão. Ele é composto por quatro categorias: phishing, desfiguração, malware e URLs benignos, abrangendo diferentes tipos de ameaças online. Cada URL é armazenada em duas colunas: uma para o link em si e outra para sua respectiva categoria.
4.2.2. Desafios e Oportunidades: Lidando com Dados Desequilibrados
Ao analisarmos o conjunto de dados, identificamos um desafio interessante: o desequilíbrio de classes. 66% das URLs são benignas, enquanto as demais categorias dividem o restante. Essa assimetria pode afetar o desempenho dos modelos, pois eles podem tender a favorecer a classe majoritária.
Em vez de corrigir o desequilíbrio, optamos por manter o conjunto de dados original. Essa escolha estratégica nos permitirá avaliar como nossos modelos e métodos de seleção de instâncias lidam com os desafios colocados por dados desequilibrados, refletindo melhor situações reais onde as classes podem não estar perfeitamente balanceadas.
4.2.3. Gerando Conjuntos de Dados: Diversidade para Treinamento Robusto
Para garantir a robustez do nosso treinamento, geramos três conjuntos de dados distintos a partir do conjunto de dados original. Cada um desses conjuntos contém aproximadamente 170.000 URLs, proporcionando uma diversidade de dados para treinar nossos modelos de forma eficaz.
Para gerar esses conjuntos de dados, utilizamos três métodos de seleção de instâncias no software MATLAB. Esses métodos nos permitiram extrair diferentes subconjuntos do conjunto de dados original, explorando diferentes perspectivas e aumentando a generalização dos modelos.
3.2.3.1. Seleção Aleatória: Rapidez e Simplicidade
O primeiro método de seleção de instâncias que exploramos foi a seleção aleatória, utilizando a função randperm no MATLAB. Essa abordagem simples e rápida selecionou cerca de 170.000 URLs aleatoriamente do conjunto de dados de treinamento, reduzindo-o de forma eficiente. A principal vantagem desse método reside na sua velocidade, levando apenas alguns segundos para ser concluído.
3.2.3.2. BPLSH: Foco nos Limites das Categorias
Em contraste com a seleção aleatória, o método BPLSH, desenvolvido por M. Aslani e S. Seipel [26], adota uma abordagem mais estratégica. Ele seleciona e retém instâncias que estão próximas dos limites entre as categorias, eliminando instâncias não essenciais que estão distantes desses limites (Figura 4).
No contexto do nosso estudo, com quatro categorias (benigno, desfiguração, phishing e malware), o BPLSH examina os limites entre essas categorias, priorizando instâncias que fornecem informações valiosas sobre as fronteiras entre as classes. Apesar de sua precisão, esse método se mostrou o mais lento, levando mais de 1,5 horas para ser concluído.
|
Método |
Vantagens |
Desvantagens |
Tempo de Execução |
|
Aleatório |
Rápido e simples |
Pode não capturar instâncias cruciais |
Segundos |
|
BPLSH |
Foco nos limites das categorias, maior precisão |
Mais lento |
Mais de 1,5 horas |
Tabela 1 - Comparação detalhada Seleção Aleatória x BPLSH
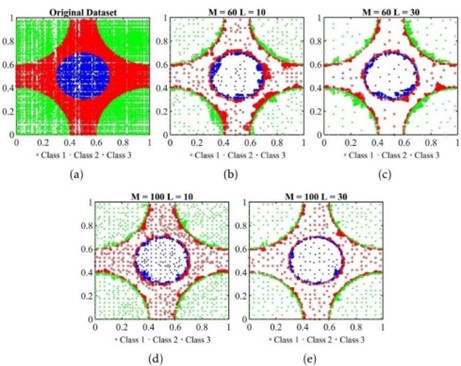
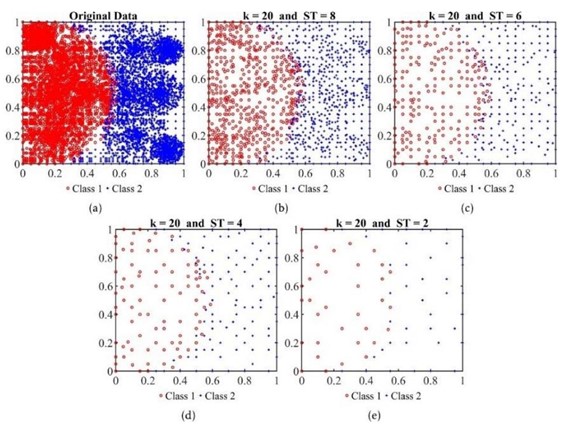
3.2.3.3. DRLSH: Reduzindo Dados com Eficiência
O DRLSH, um método de seleção de dados desenvolvido por M. Aslani e S. Seipel [27], se junta à nossa jornada na detecção de URLs maliciosos. Sua principal função é identificar e eliminar amostras semelhantes, otimizando o processo de treinamento.
Velocidade e Precisão em Equilíbrio:
Em contraste com o BPLSH, o DRLSH se destaca pela sua velocidade superior. Ele é capaz de reduzir a quantidade de dados (Figura 5) de forma mais rápida, especialmente em casos onde duas categorias possuem amostras com características similares. Essa otimização pode levar a um treinamento mais veloz dos modelos.
Funcionamento Detalhado:
No contexto do nosso estudo, com quatro categorias (benigno, desfiguração, phishing e malware), o DRLSH examina as amostras semelhantes, identificando aquelas que podem ser eliminadas sem comprometer a precisão do modelo. Essa abordagem garante que apenas as informações mais relevantes sejam utilizadas no treinamento, otimizando o processo e liberando recursos computacionais.
Tempo de Execução Eficaz:
Em comparação com o BPLSH, o DRLSH se destaca pela sua agilidade. A redução de dados utilizando este método leva apenas de 10 a 15 minutos, significativamente menor do que as mais de 1,5 horas do BPLSH. Essa eficiência de tempo torna o DRLSH uma opção interessante para grandes conjuntos de dados, onde a velocidade é um fator crucial.
|
Método |
Descrição |
Vantagens |
Desvantagens
|
Tempo de Execução |
|
Aleatório |
Seleciona URLs aleatoriamente do conjunto de dados de treinamento. |
Rápido e simples. |
Pode não capturar instâncias cruciais. |
Segundos |
|
BPLSH |
Foco nos limites entre as categorias, maior precisão. |
Maior precisão ao focar nos limites entre as categorias. |
Mais lento. |
Mais de 1,5 horas |
|
DRLSH |
Identifica e elimina amostras semelhantes. |
Mais rápido que o BPLSH, reduz redundância de dados. |
Pode não ser tão preciso quanto o BPLSH. |
10 a 15 minutos |
Tabela 2 - Tabela Comparativa de Métodos de Seleção de Instâncias
4.2.4. Engenharia de recursos
Neste estudo, 16 recursos diferentes foram utilizados para treinar e aprender modelos de aprendizado de máquina, juntamente com um recurso de saída (Tabela 3).
|
Recurso |
Tipo de dados |
Descrição |
|
Tipo (recurso de saída) |
Categórico |
A categorização do tipo de URL é baseada se é phishing, desfiguração, malware ou benigno. |
|
URL_comprimento |
Numérico |
O comprimento de um determinado URL. |
|
comprimento_domínio |
Numérico |
O comprimento do nome de domínio. |
|
Tem_ipv4 |
Numérico |
Verificando a presença de um endereço IPv4 em cada URL e posteriormente retornando 1 ou 0. |
|
Tem_http |
Numérico |
Verificando a presença do protocolo HTTP em cada URL e posteriormente retornando 1 ou 0. |
|
Tem_https |
Numérico |
Verificando a presença do protocolo HTTPS em cada URL e posteriormente retornando 1 ou 0. |
|
Contagem_pontos |
Numérico |
Cálculo do número de pontos. |
|
Contagem_traços |
Numérico |
Cálculo do número de travessões. |
|
Contagem_sublinhados |
Numérico |
Cálculo do número de sublinhados. |
|
Contagem_barras |
Numérico |
Cálculo do número de barras. |
|
Contagem_ques |
Numérico |
Cálculo do número de pontos de interrogação. |
|
Contagem_não_alfanumérica |
Numérico |
Cálculo de caracteres não alfanuméricos. |
|
Contagem_dígitos |
Numérico |
Cálculo do número de dígitos. |
|
Contagem_letras |
Numérico |
Cálculo do número de letras. |
|
Contagem_params |
Numérico |
Cálculo do número de parâmetros. |
|
Has_php |
Numérico |
Verificando a presença da palavra “php” em cada URL e posteriormente retornando 1 ou 0. |
|
Tem_html |
Numérico |
Verificando a presença da palavra “html” em cada URL e posteriormente retornando 1 ou 0. |
Tabela 3 - Lista de recursos.
4.2.5. Modelos
Nossa jornada na detecção de URLs maliciosos continua com a exploração de quatro modelos de aprendizado de máquina: Árvore de Decisão (DT), Floresta Aleatória (RF), K-Nearest Neighbors (KNNs) e Máquina de Vetores de Suporte (SVM). Cada um desses modelos possui características e vantagens únicas, tornando-os ferramentas valiosas para a tarefa de classificação.
4.2.6. Árvore de Decisão: Desvendando a Simplicidade e a Eficiência
A Árvore de Decisão (DT) se destaca por sua simplicidade e facilidade de interpretação. Esse modelo constrói uma estrutura em forma de árvore, onde cada nó representa uma decisão a ser tomada com base nos valores dos recursos. Essa abordagem intuitiva permite identificar facilmente os fatores que mais influenciam o resultado final [28, p. 2094].
Para otimizar o desempenho da DT, utilizamos a otimização bayesiana, buscando a combinação ideal de hiperparâmetros que maximizam a precisão do modelo. O número máximo de nós na árvore foi limitado a 1, visando reduzir a complexidade e evitar o overfitting.
O critério de divisão Gini [28, p. 2095] foi utilizado para avaliar a qualidade das divisões na árvore. Esse critério mede a impureza das classes em cada nó, indicando o quão bem a árvore separa os dados em diferentes categorias.
3.2.6.1. K-Nearest Neighbors: Colocando o Poder da Proximidade em Ação
O K-Nearest Neighbors (KNNs) baseia-se na intuição de que pontos de dados semelhantes tendem a pertencer à mesma classe. Para classificar uma nova amostra, o KNNs identifica os k vizinhos mais próximos no conjunto de dados de treinamento e atribui a classe majoritária entre esses vizinhos à nova amostra [29, p. 19].
A otimização bayesiana foi utilizada para ajustar o hiperparâmetro crucial do KNNs: o número de vizinhos (k). Neste estudo, o valor de k foi definido como 1, indicando que apenas o vizinho mais próximo foi considerado para a classificação.
A distância Euclidiana [29, p. 20] foi utilizada para calcular a similaridade entre os pontos de dados. Essa métrica mede a distância em linha reta entre dois pontos no espaço multidimensional, considerando todas as suas características.
3.2.6.2. Floresta Aleatória: Combinando Diversidade para Maior Precisão
A Floresta Aleatória (RF) expande o conceito da DT ao combinar múltiplas árvores de decisão em um único modelo. Cada árvore é treinada em um subconjunto aleatório dos dados e das características, gerando um conjunto diversificado de previsões. A classe final é definida pela maioria de votos entre as árvores [30, p. 87].
A otimização bayesiana foi utilizada para ajustar o número de árvores na floresta e a taxa de aprendizado, hiperparâmetros que influenciam a diversidade e a precisão do modelo.
3.2.6.3. Máquina de Vetores de Suporte: Encontrando Fronteiras Ótimas
A Máquina de Vetores de Suporte (SVM) busca encontrar um hiperplano no espaço de alta dimensão que separa as diferentes classes de forma otimizada. Esse hiperplano é definido pelos pontos de suporte, que são os pontos de dados mais próximos da fronteira entre as classes [31, p. 167].
A otimização bayesiana foi utilizada para ajustar o parâmetro C, que controla a margem de erro do hiperplano. Um valor alto de C permite um hiperplano mais flexível, enquanto um valor baixo o torna mais restritivo.
4.3. Resultados: Desvendando o Desempenho dos Modelos
Nesta seção, embarcamos em uma jornada para explorar os resultados obtidos pelos quatro modelos de aprendizado de máquina (DT, RF, KNNs e SVM) em cada um dos três conjuntos de dados. Nosso objetivo é avaliar o desempenho e a precisão de cada modelo, buscando identificar o melhor candidato para a tarefa de detecção de URLs maliciosos.
4.3.1. Ajuste de Hiperparâmetros: A Busca pela Perfeição
Para alcançar o pico de desempenho, mergulhamos no processo de ajuste de hiperparâmetros. Utilizamos o conjunto de dados de treinamento para treinar cada modelo, experimentando diferentes configurações para seus hiperparâmetros. Essa busca meticulosa nos permitiu encontrar a combinação ideal de parâmetros para cada modelo, maximizando sua precisão.
A otimização bayesiana foi nossa aliada nesse processo, guiando-nos na jornada para encontrar os melhores hiperparâmetros. Os resultados dessa otimização foram compilados na Tabela 2, revelando os hiperparâmetros pontuais para cada modelo.
4.3.2. Validação Cruzada K-fold: Equilíbrio Entre Precisão e Eficiência
Optamos por utilizar a validação cruzada K-fold com K definido como 5. Essa escolha se baseia na ampla aceitação e na prática padrão que a validação cruzada de 5 vezes oferece. Ela encontra um equilíbrio ideal entre estimar com precisão o desempenho do modelo e gerenciar os custos computacionais envolvidos no processo.
O modelo foi treinado e avaliado cinco vezes, e a média dos resultados foi calculada para determinar os melhores hiperparâmetros pontuais. Essa abordagem robusta garante que nossas conclusões sejam confiáveis e representem o desempenho geral do modelo.
4.3.3. Hiperparâmetros sob Análise: Uma Visão Detalhada
Cada modelo possui um conjunto único de hiperparâmetros que influenciam seu comportamento. Vamos explorar os hiperparâmetros de cada modelo em detalhes:
- Árvore de Decisão (DT):
- Número Máximo de Divisões: Define o limite superior para o número de divisões na árvore, controlando a complexidade do modelo e evitando overfitting.
- Critério de Divisão: Determina o método utilizado para selecionar o recurso que melhor separa as classes em cada nó da árvore.
- K-Nearest Neighbors (KNNs):
- Número de Vizinhos: Define o número de pontos de dados mais próximos que serão considerados para classificar um novo ponto de dados.
- Peso da Distância: Estabelece como a distância entre os pontos de dados influencia a classificação, com valores mais altos indicando maior influência para pontos mais próximos.
- Floresta Aleatória (RF):
- Método Ensemble: Controla a estratégia utilizada para combinar as previsões de múltiplas árvores de decisão, reduzindo o overfitting e melhorando a generalização do modelo.
- Número de Árvores: Define o número de árvores de decisão a serem criadas na floresta aleatória.
- Número Máximo de Divisões: Limita o número máximo de divisões em cada árvore, controlando sua complexidade.
- Número de Preditores a Serem Amostrados: Determina quantos preditores (atributos) serão selecionados aleatoriamente em cada ponto de divisão na árvore.
- Máquina de Vetores de Suporte (SVM):
- Método Multiclasse: Define a estratégia utilizada para lidar com a classificação multiclasse, com "One-vs-One" criando vários classificadores binários para comparar classes par a par.
- Nível de Restrição de Caixa: Regula o compromisso entre um baixo erro de treinamento e um limite de decisão mais simples, influenciando a complexidade do modelo.
- Escala do Kernel: Controla o alcance ou influência de cada ponto de dados no espaço de recursos, ajustando a sensibilidade do modelo.
- Função Kernel: Especifica o tipo de transformação aplicada aos pontos de dados, com o kernel gaussiano escolhido neste caso.
- Padronizar Dados: Determina se os recursos de entrada serão padronizados antes do treinamento do modelo, garantindo uma escala uniforme.
|
Modelo |
Melhores hiperparâmetros de ponto |
Tempo de sintonia |
|
DT |
Número máximo de divisões: 36951 Critério de divisão: índice de diversidade de Gini |
8 minutos |
|
KNNs |
Número de vizinhos: 10 Peso da distância: Inverso ao quadrado |
21 horas |
|
RF |
Método de conjunto: Bolsa Número de alunos: 11 Número máximo de divisões: 34067 Número de preditores para amostrar: 6 |
2 horas |
|
SVM |
Método multiclasse: Nível de restrição One-vs-One Box: 943,1384 Escala do kernel: 2,8684 Função do kernel: Gaussiano Padronizar dados: verdadeiro |
46 horas |
Tabela 4 - Hiperparâmetros de melhor ponto do modelo e tempo de ajuste
4.3.4. Conjunto de dados de teste
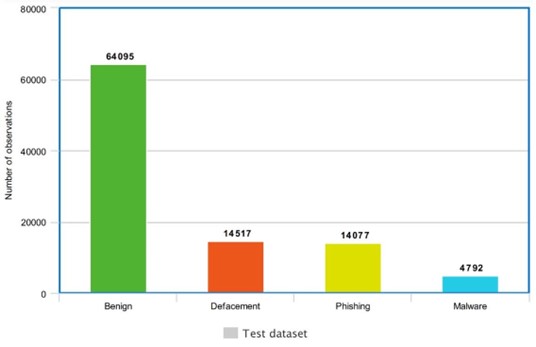
Nossa jornada finalmente chega ao ponto crucial: a fase de testes. Para avaliar o desempenho real dos modelos, utilizamos um conjunto de dados de teste composto por aproximadamente 97.500 URLs, representando 15% do conjunto de dados original.
Cada categoria dentro do conjunto de dados de teste possui um número variável de observações, refletindo a distribuição real das URLs na internet. Essa diversidade garante que os modelos sejam desafiados com uma ampla gama de exemplos, testando sua capacidade de generalização para situações do mundo real.
O conjunto de dados de teste foi utilizado para avaliar cada modelo em cada método de seleção de instância (Figura 6). Essa abordagem multifacetada nos permite analisar como os modelos se comportam em diferentes contextos, fornecendo uma visão completa de suas capacidades.
4.3.5. Conjunto de Dados Aleatório: Desequilíbrio e Desafios
Nesta seção, embarcamos em uma análise do conjunto de dados aleatório, gerado utilizando os métodos de seleção de instâncias e posteriormente utilizado para treinar os modelos. Ao explorar este conjunto de dados, descobrimos um desequilíbrio significativo nas classes.
- Seleção Aleatória: Uma Amostragem Neutra?
Ao aplicar a seleção aleatória, cerca de 170.000 amostras foram selecionadas do conjunto de dados de treinamento. No entanto, essa seleção aleatória não representou fielmente a distribuição real das classes. A maioria das amostras selecionadas pertencia à categoria de URLs benignas (Figura 7).
- Desafios do Desequilíbrio:Esse desequilíbrio nas classes apresenta desafios para os modelos de aprendizado de máquina. Modelos treinados em conjuntos de dados desequilibrados podem tender a favorecer a classe majoritária (URLs benignas), negligenciando as classes minoritárias (malware, phishing, desfiguração). Isso pode levar a um desempenho precário na detecção de URLs maliciosas, que são justamente as mais importantes a serem identificadas.
- Mitigando o Desequilíbrio:Para lidar com esse desequilíbrio, podemos empregar diversas técnicas, como:
- Amostragem Ressampleada: Essa técnica pode aumentar artificialmente o número de amostras das classes minoritárias, criando um conjunto de dados mais balanceado.
- Algoritmos de Aprendizado Adaptativo: Alguns algoritmos de aprendizado de máquina, como o "Random Forest" e o "AdaBoost", podem ser configurados para dar mais peso às classes minoritárias durante o treinamento.
- Métricas de Avaliação Apropriadas: Ao avaliar o desempenho dos modelos em conjuntos de dados desequilibrados, é crucial utilizar métricas que considerem o desempenho em todas as classes, como a F1-score e a AUC.


RF apresenta a maior precisão em comparação com os outros modelos (Tabela 5). Além disso, considerando o tempo de treinamento relativamente curto, este modelo pode ser considerado a melhor escolha como modelo ideal para este método de seleção de instâncias.
|
Modelo
|
Precisão do treinamento |
Precisão do teste |
Tempo de treino |
|
RF |
94,1% |
94,4% |
71 segundos |
|
SVM |
93,5% |
93,8% |
10.793 segundos |
|
DT |
93,0% |
93,1% |
16 segundos |
|
KNNs |
89,8% |
90,2% |
94 segundos |
Tabela 5 - Precisão de treinamento, teste do modelo e tempo de treinamento
As matrizes de confusão, ferramentas valiosas na avaliação de modelos de aprendizado de máquina, fornecem insights cruciais sobre o desempenho de cada modelo em um conjunto de dados de teste. Nesta seção, embarcamos em uma jornada para desvendar os segredos das matrizes de confusão para cada modelo que testamos.
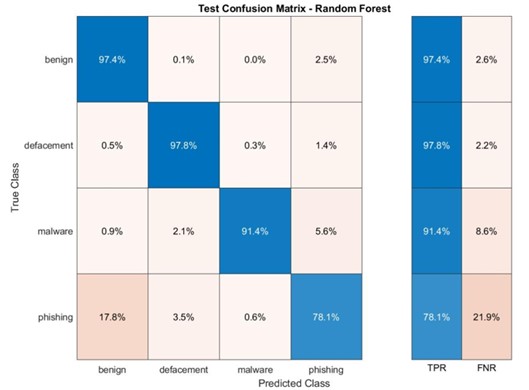
RF: Um Guerreiro Robusto, Exceto Contra o Malware
A matriz de confusão para o modelo RF revela um desempenho excepcional em todas as categorias, exceto para URLs de malware (Apêndice A). As taxas de precisão ultrapassam 90% para URLs benignos, phishing e desfigurados, demonstrando a robustez do modelo em identificar corretamente a maioria das amostras. No entanto, o RF enfrenta um desafio com URLs de malware. A matriz de confusão indica que o modelo classifica incorretamente alguns URLs de malware como phishing. Essa imprecisão pode ter consequências sérias, pois pode levar à falha na identificação de ameaças reais.
DT: Precisão Geral, Exceção no Malware e Phishing
Similar ao RF, o modelo DT apresenta alta precisão na maioria das categorias, com taxas acima de 90% para URLs benignos, desfigurados e phishing (Apêndice A). No entanto, o DT também enfrenta dificuldades com URLs de malware, exibindo um certo grau de imprecisão ao classificar incorretamente alguns como phishing. Essa imprecisão em distinguir malware de phishing, embora menor que a do RF, ainda pode representar um risco, pois pode levar à categorização incorreta de ameaças.
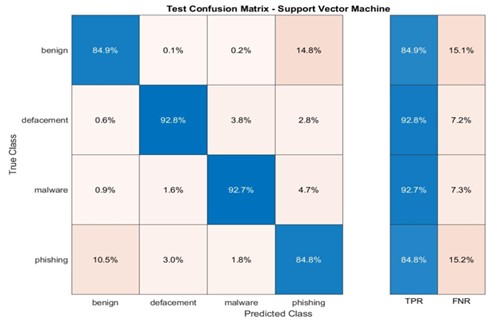
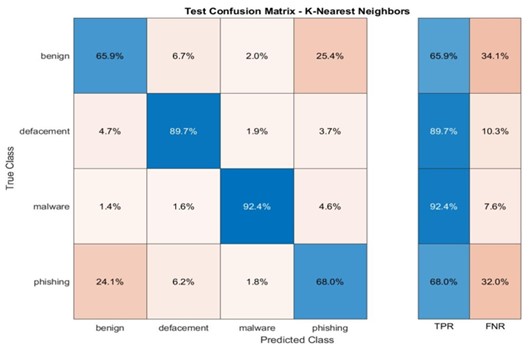
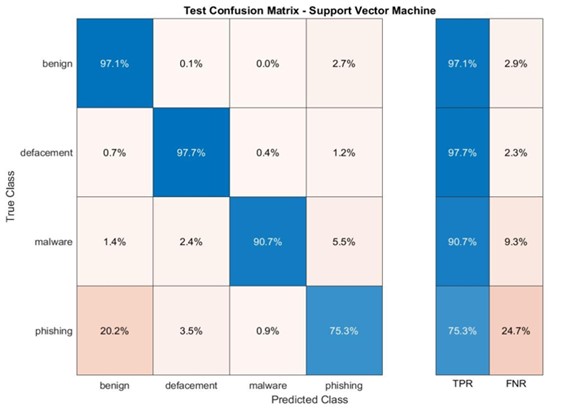
SVM e KNN: Brilhando em URLs Benignos e Desfigurados, Mas Lutando com Malware e Phishing
As matrizes de confusão para os modelos SVM e KNN revelam que estes modelos alcançam alta precisão na previsão de URLs benignos e desfigurados (Apêndice B). Essa performance robusta indica que os modelos são eficazes em identificar corretamente a maioria das amostras nessas categorias.
No entanto, tanto o SVM quanto o KNN demonstram precisões mais baixas nas categorias de malware e phishing. As matrizes de confusão indicam que esses modelos lutam para distinguir com precisão entre essas duas categorias, o que pode levar à falha na identificação de ameaças reais.
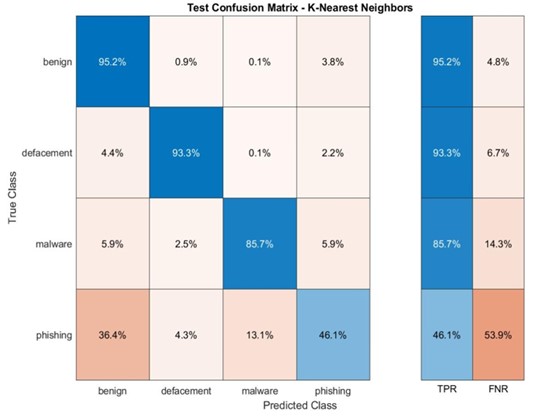
4.3.6. Conjunto de Dados DRLSH: Diversidade e Desafios
Nesta seção, embarcamos em uma análise do conjunto de dados DRLSH, gerado através do método DRLSH e posteriormente utilizado para treinar os modelos. Ao explorar este conjunto de dados, descobrimos características únicas que influenciam o desempenho dos modelos.
DRLSH: Seleção Estratégica de Amostras
O método DRLSH foi aplicado para gerar o conjunto de dados, selecionando cerca de 170.000 amostras dentre as quatro categorias de URLs. A principal característica desse conjunto de dados reside na diversidade das amostras selecionadas. Ao contrário do conjunto de dados aleatório, onde a maioria das amostras pertencia à categoria de URLs benignas, o DRLSH priorizou a seleção de amostras dissimilares entre si (Figura 8).

O modelo SVM obteve maiores precisões tanto nas fases de treinamento quanto de teste em comparação aos demais modelos (Tabela 6).
|
Modelo |
Precisão do Treinamento |
Precisão do Teste |
Tempo de Treino |
|
SVM |
90,90% |
92,40% |
18.390 segundos |
|
RF |
90,90% |
90,10% |
82 segundos |
|
DT |
87,70% |
87,70% |
21 segundos |
|
KNNs |
80,80% |
87,40% |
92 segundos |
Tabela 6 - Precisão de treinamento, teste do modelo e tempo de treinamento.
RF e DT: Desempenho Misto, Brilhando em Benignos e Desfigurados
As matrizes de confusão para os modelos RF e DT revelam um padrão similar ao observado no conjunto de dados aleatório (Apêndice C). Ambos os modelos alcançam alta precisão na previsão de URLs benignos e desfigurados, com taxas acima de 90% em alguns casos. Essa performance robusta indica que os modelos são eficazes em identificar corretamente a maioria das amostras nessas categorias.
No entanto, tanto o RF quanto o DT apresentam dificuldades com URLs de malware e phishing. As matrizes de confusão indicam que esses modelos lutam para distinguir com precisão entre essas duas categorias, o que pode levar à falha na identificação de ameaças reais. Essa dificuldade pode ser atribuída à diversidade das amostras no conjunto de dados DRLSH, onde as classes minoritárias (malware, phishing) são menos representadas.
SVM e KNN: Benignos e Desfigurados Dominam, Mas Malware e Phishing Resistem
As matrizes de confusão para os modelos SVM e KNNs no conjunto de dados DRLSH apresentam resultados semelhantes aos observados no conjunto de dados aleatório (Apêndice D). Ambos os modelos alcançam maior precisão na previsão de URLs benignos e desfigurados, com taxas acima de 90% em alguns casos.
No entanto, as outras duas categorias, malware e phishing, apresentam precisões inferiores. As matrizes de confusão indicam que esses modelos lutam para distinguir com precisão entre essas duas categorias, repetindo o desafio observado com os modelos RF e DT.
4.3.7. Conjunto de Dados BPLSH: Ambiguidade e Desafios
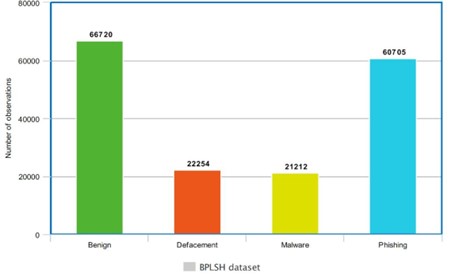
Nesta seção, embarcamos em uma análise do conjunto de dados BPLSH, gerado através do método BPLSH e posteriormente utilizado para treinar os modelos. Ao explorar este conjunto de dados, descobrimos características únicas que influenciam o desempenho dos modelos.
- BPLSH: Seleção Estratégica de Amostras nos Limites
O método BPLSH foi aplicado para gerar o conjunto de dados, selecionando cerca de 170.000 amostras dentre as quatro categorias de URLs. A principal característica desse conjunto de dados reside na seleção de amostras que estão mais próximas dos limites entre as categorias. Essa estratégia visa capturar URLs que apresentam características ambíguas, dificultando sua classificação precisa.
- Desafios da Ambiguidade:
Essa seleção de amostras nos limites das categorias, embora interessante para avaliar a robustez dos modelos, pode apresentar desafios para o aprendizado de máquina. Modelos treinados em conjuntos de dados com alta ambiguidade podem ter dificuldade em identificar padrões claros e consistentes entre as categorias, especialmente quando as classes minoritárias (malware, phishing, desfiguração) são menos representadas.
- Mitigando os Desafios:
Para lidar com esses desafios, podemos empregar diversas técnicas, como:
- Algoritmos de Aprendizado Adaptativo: Alguns algoritmos, como o "AdaBoost" e o "XGBoost", podem ser configurados para lidar com conjuntos de dados ambíguos, ajustando seu comportamento de acordo com a distribuição das classes e a incerteza nas amostras.
- Métodos de Ensemble: Combinar vários modelos com diferentes pontos fortes pode levar a um melhor desempenho geral, especialmente em conjuntos de dados desafiadores com alta ambiguidade.
- Técnicas de Pré-processamento: Técnicas como a normalização e a redução de dimensionalidade podem ajudar a tornar as características das amostras mais claras e facilitar a distinção entre as categorias
(Figura 9).

O modelo RF apresentou a maior precisão de teste entre todos os modelos (Tabela 7). Isto sugere que o modelo RF é mais adequado para lidar com novos conjuntos de dados do que outros modelos. No entanto, a precisão geral do método foi inferior à de outros métodos de seleção de instâncias.
|
Modelo |
Precisão do treinamento |
Precisão do teste |
Tempo de treino |
|
RF |
83,9% |
88,1% |
75 segundos |
|
SVM
|
83,3% |
86,5% |
16.681 segundos |
|
DT |
82,6% |
83,5% |
23 segundos |
|
KNNs |
78,6% |
71,1% |
88 segundos |
Tabela 7 - Precisão de treinamento, teste do modelo e tempo de treinamento.
As matrizes de confusão para os modelos de Floresta Aleatória (RF) e Árvore de Decisão (DT) mostram que esses modelos conseguiram prever com precisão URLs relacionadas a desfiguração e malware (veja Apêndice E). Contudo, a precisão para outras categorias foi inferior a 90%. A matriz de confusão para o modelo de Máquina de Vetores de Suporte (SVM) indica que este modelo teve uma precisão de cerca de 92% na previsão de URLs de desfiguração e malware, mas as outras duas categorias não alcançaram 90% de precisão (veja Apêndice F). Por sua vez, a matriz de confusão para o modelo K-Nearest Neighbors (KNN) mostra que ele se saiu melhor na previsão de URLs de malware em comparação com as demais categorias, com uma precisão de 92,4%.
4.3.8. Um Elemento Crucial na Detecção de URLs Maliciosos
O recurso "has_http" se destaca como o elemento mais crucial na identificação de URLs maliciosos, conforme demonstrado na Figura 10. Essa importância se deve ao fato de que URLs que utilizam o protocolo HTTP não possuem criptografia, tornando-os altamente propensos a serem maliciosos.
Para determinar a relevância de cada recurso, foi empregado o algoritmo MRMR (Máxima Relevância com Redundância Mínima). O MRMR se baseia em medidas estatísticas para realizar a seleção de recursos, atribuindo valores que representam a pontuação total do algoritmo para cada recurso em todos os três conjuntos de dados gerados pelos métodos de seleção de instâncias.
Em resumo, o recurso "has_http" assume um papel fundamental na detecção de URLs maliciosos, devido à sua capacidade de identificar URLs que não possuem criptografia e, consequentemente, apresentam maior probabilidade de serem maliciosos. A utilização do algoritmo MRMR para determinar a importância dos recursos garante a seleção dos elementos mais relevantes e informativos para a classificação de URLs.
Pontos chave:

O recurso "has_http" é o mais importante para identificar URLs maliciosos. URLs que usam HTTP não são criptografados e são mais propensos a serem maliciosos. O algoritmo MRMR é utilizado para determinar a importância dos recursos. O MRMR seleciona os recursos mais relevantes e informativos para a classificação de URLs.
4.4. Discussão: Limitações dos Métodos BPLSH e DRLSH para Redução de Conjuntos Desequilibrados
Nossa análise revelou que os métodos de seleção de instâncias BPLSH e DRLSH apresentam limitações significativas na manipulação de conjuntos de dados desequilibrados. A principal falha reside na tendência desses métodos de selecionar predominantemente amostras da categoria majoritária, negligenciando as categorias minoritárias. Essa falha fundamental resulta em um desempenho precário para a classificação das categorias minoritárias, impactando negativamente a precisão geral do modelo.
- Explicação detalhada das limitações:
- Viés na seleção de amostras: BPLSH e DRLSH favorecem a seleção de amostras da categoria majoritária, levando a uma sub-representação das categorias minoritárias no conjunto de dados reduzido. Essa sub-representação impede o modelo de aprender efetivamente as características das categorias minoritárias, resultando em classificações incorretas.
- Degradação da performance: O viés na seleção de amostras impacta negativamente a performance do modelo, especialmente para as categorias minoritárias. A baixa quantidade de amostras dessas categorias no conjunto de dados reduzido limita a capacidade do modelo de generalizar para novos dados, levando a um aumento das taxas de erro.
- Incompatibilidade com dados desequilibrados: Em suma, os métodos BPLSH e DRLSH não são adequados para lidar com conjuntos de dados desequilibrados, pois não conseguem balancear a distribuição das amostras entre as categorias. Essa incompatibilidade os torna impróprios para tarefas de classificação que envolvem categorias minoritárias significativas.
|
Modelo |
Precisão do treinamento |
Precisão do teste |
Tempo de treino |
|
RF |
94,1% |
94, 4% |
71 segundos |
|
SVM |
93,5% |
93,8% |
10.793 segundos |
|
DT |
93,0% |
93,1% |
16 segundos |
|
KNNs |
89,8% |
90,2% |
94 segundos |
Tabela 8 - Precisão de treinamento, teste do modelo e tempo de treinamento em conjunto de dados aleatório.
|
Modelo |
Precisão do treinamento |
Precisão do teste |
Tempo de treino |
|
RF |
83,9% |
88,1% |
75 segundos |
|
SVM |
83,3% |
86,5% |
16.681 segundos |
|
DT |
82,6% |
83,5% |
23 segundos |
|
KNNs |
78,6% |
71,1% |
88 segundos |
Tabela 9 - Precisão de treinamento, teste do modelo e tempo de treinamento no conjunto de dados DRLSH.
|
Modelo |
Precisão do treinamento |
Precisão do teste |
Tempo de treino |
|
RF |
83,9% |
88,1% |
75 segundos |
|
SVM |
83,3% |
86,5% |
16.681 segundos |
|
DT |
82,6% |
83,5% |
23 segundos |
|
KNNs |
78,6% |
71,1% |
88 segundos |
Tabela 10 - Precisão de treinamento, teste do modelo e tempo de treinamento no conjunto de dados BPLSH.
- Seleção de Instâncias e Impacto nos Resultados:
A aplicação de três métodos distintos de seleção de instâncias (aleatório, DRLSH e BPLSH) para reduzir o conjunto de dados revelou um desafio crucial: alcançar uma seleção justa de instâncias pode ser extremamente desafiador, com um impacto significativo nos resultados. Essa dificuldade resultou em um desempenho de classificação precário, evidenciando a importância de iniciar o estudo com um conjunto de dados mais equilibrado.
Infelizmente, devido a restrições de tempo, não foi possível coletar um conjunto de dados suficientemente grande para todas as quatro categorias de URLs. Essa limitação representa um potencial para aprimoramento do estudo com mais tempo e recursos.
- Desafios Computacionais e Limitações de Tempo:
Um exemplo das dificuldades computacionais enfrentadas foi o ajuste de hiperparâmetros para o SVM, que demandou aproximadamente 46 horas de operação contínua do computador pessoal e um uso substancial de espaço de memória remota. Durante a fase de treinamento, diversos casos de interrupção do processo ocorreram devido à insuficiência de memória na área de trabalho remota, exigindo a reinicialização do procedimento.
- Expectativas e Resultados Inesperados:
Inicialmente, havia a expectativa de que os métodos BPLSH e DRLSH de seleção de instâncias apresentariam precisões superiores em comparação com o método aleatório. Essa expectativa se baseava na suposição de que esses métodos poderiam selecionar limites e eliminar amostras semelhantes, otimizando potencialmente o processo de treinamento. No entanto, contrariamente às expectativas, o método aleatório resultou nas maiores precisões.
- Desempenho Diferenciado dos Modelos:
Observou-se um desempenho variável dos modelos entre os conjuntos de dados. SVM e RF alcançaram precisões superiores em comparação com KNN e DT. Considerando os tempos de treinamento e ajuste de hiperparâmetros, a RF se destaca como a escolha mais favorável. Não foram encontrados problemas durante as fases de ajuste e treinamento da RF, e resultados satisfatórios foram obtidos na primeira tentativa. Em contrapartida, o SVM se mostrou consideravelmente mais lento, levando a problemas durante o treinamento e, em alguns casos, à interrupção do processo devido a restrições de recursos de memória.
|
Modelo |
Melhores hiperparâmetros de ponto |
Tempo de sintonia |
|
DT |
Número máximo de divisões: 36951 |
8 minutos |
|
Critério de divisão: índice de diversidade de Gini |
||
|
KNNs |
Número de vizinhos: 10 |
21 horas |
|
Peso da distância: inverso ao quadrado |
||
|
RF |
Método de conjunto: Bolsa |
2 horas |
|
Número de alunos: 11 |
||
|
Número máximo de divisões: 34067 |
||
|
Número de preditores para amostra: 6 |
||
|
SVM |
Método multiclasse: Um contra Um |
46 horas |
|
Nível de restrição de caixa: 943.1384 |
||
|
Escala do kernel: 2,8684 |
||
|
Função do kernel: Gaussiano |
||
|
Padronizar dados: verdadeiro |
Tabela 11 - Hiperparâmetros de melhor ponto do modelo e tempo de ajuste
- Recomendação do Modelo:
A escolha do modelo ideal entre RF e SVM depende das prioridades do estudo:
- Resultados rápidos e imediatos: Se o tempo é crucial e resultados rápidos são necessários, o RF se destaca como a melhor opção devido ao seu menor tempo de treinamento e ajuste de hiperparâmetros.
- Maior precisão, mesmo com tempo de treinamento mais longo: Se a precisão máxima do teste é fundamental e o tempo de processamento não é uma restrição significativa, o SVM apresenta-se como a escolha ideal, apesar de exigir um tempo de treinamento e ajuste de hiperparâmetros mais extenso.
- Ética na Engenharia:
A ética do engenheiro assume relevância crucial neste estudo, pois a decisão de classificar URLs como maliciosas ou benignas pode ter consequências significativas para os usuários. É fundamental considerar as implicações de classificações incorretas:
- Falsos Negativos: Uma URL maliciosa classificada como benigna pode induzir os usuários a clicar nela, expondo-os a riscos cibernéticos.
- Falsos Positivos: Um URL benigno classificado como malicioso pode bloquear o acesso a páginas úteis, causando inconveniências e frustrações.
Para mitigar esses riscos, os modelos de aprendizado automático utilizados na classificação de URLs devem ser rigorosamente testados e validados para garantir seu funcionamento adequado. Isso envolve testes com um grande conjunto de URLs para garantir a precisão e confiabilidade das classificações.
- Impacto na Segurança Cibernética:
A identificação e o bloqueio de URLs maliciosos contribuem significativamente para a segurança cibernética, protegendo os usuários contra diversas ameaças online. Essa proteção, por sua vez, reduz o risco de danos financeiros e promove um ambiente digital mais estável e sustentável. Segundo previsões, os custos do cibercrime aumentarão anualmente em 15% até 2025, alcançando US$ 10,5 trilhões.
- Desafios e Melhorias Futuras:
O estudo enfrentou alguns desafios:
- Problemas com o Jupyter Notebook: A geração de figuras como a matriz de confusão no Jupyter Notebook apresentou dificuldades, limitando a capacidade de apresentar e analisar os resultados de forma eficaz.
- Restrições de memória: As restrições de memória durante o treinamento do modelo, especialmente com KNNs e SVM, exigiram a utilização do MATLAB em um desktop remoto compartilhado, gerando desafios adicionais devido ao tempo de treinamento extenso.
Para aprimorar o estudo em futuras pesquisas, as seguintes medidas podem ser consideradas:
- Conjunto de dados maior e equilibrado: A coleta de um conjunto de dados mais amplo com representação balanceada de todos os tipos de URLs maliciosos (benignos, desfigurados, phishing e malware) permitiria que os modelos classificassem e identificassem URLs com maior precisão, proporcionando uma avaliação mais abrangente.
- Exploração de novos modelos: A inclusão de modelos como redes neurais, NB, XGBoost e LGBoost permitiria a investigação de alternativas que podem oferecer desempenho superior na identificação de URLs maliciosos.
Consideração de novas categorias de URLs maliciosos: A expansão do estudo para incluir categorias como Redirect-URL, Scam-URL, Clickbait-URL e Drive-by Downloads-URL ampliaria o escopo da pesquisa e forneceria insights sobre os desafios de classificar diversos tipos de URLs maliciosos, contribuindo para o desenvolvimento de medidas de cibersegurança mais eficazes.
5. Conclusão
- Desvendando os Resultados:
A análise aprofundada dos resultados revela insights cruciais sobre a seleção de instâncias e o desempenho dos modelos:
- Método Aleatório: Eficiência e Precisão Inesperadas: O método aleatório de seleção de instâncias se destacou por sua rapidez na seleção de dados e, surpreendentemente, por alcançar a maior precisão em comparação com BPLSH e DRLSH. Essa descoberta inesperada sugere que a seleção aleatória pode ser mais eficaz para conjuntos de dados desequilibrados, como o utilizado neste estudo.
- Impacto do Conjunto de Dados Desequilibrado: O desequilíbrio nas categorias do conjunto de dados pode ter impactado negativamente o desempenho de BPLSH e DRLSH. A seleção inadequada de amostras em cada categoria, resultante do desequilíbrio, pode ter comprometido a precisão dos modelos.
- Influência do Tamanho do Conjunto de Dados e da Seleção de Instâncias: A performance dos diferentes modelos de aprendizado de máquina variou entre os conjuntos de dados. Isso indica que o número de observações em cada categoria e as URLs selecionadas em cada conjunto pelos métodos de seleção de instâncias influenciaram significativamente a precisão.
- SVM e RF: Liderando o Desempenho: Em média, o SVM se destacou com a maior precisão média de teste (90,9%), seguido pelo RF (90,8%). Ambos os modelos demonstraram forte potencial para a classificação de URLs maliciosos.
- O Poder dos Recursos Relevantes:
A análise dos recursos revelou duas características cruciais para a identificação de URLs maliciosos:
- "has_http": Um Indicador Essencial: O recurso "has_http" se consolidou como o elemento mais significativo, indicando se URLs não estavam criptografados e, consequentemente, apresentavam alta probabilidade de serem maliciosos. A ausência de criptografia torna esses URLs mais vulneráveis a ataques cibernéticos.
- "has_html": Revelando URLs Desfiguradas: O recurso "has_html" também desempenhou um papel importante na classificação de URLs desfigurados. A presença do termo "html" nos endereços dessas URLs serviu como um indicador útil para sua identificação.
- Caminhos Futuros para Aprimorar a Classificação:
Com base nos resultados e insights obtidos, este estudo abre portas para pesquisas futuras em diversas áreas:
- Combate ao Desequilíbrio dos Dados: A investigação de técnicas eficazes para lidar com conjuntos de dados desequilibrados, como subamostragem, sobreamostragem ou métodos híbridos, pode contribuir para aprimorar o desempenho dos modelos.
- Exploração de Novos Métodos de Seleção de Instâncias: A avaliação de alternativas para a seleção de instâncias, como métodos baseados em similaridade ou métodos que consideram o desequilíbrio das classes, pode levar à descoberta de abordagens mais eficientes.
- Desenvolvimento de Modelos Mais Robustos: A investigação de novos modelos de aprendizado de máquina, como redes neurais profundas ou modelos de ensemble, pode potencializar a precisão e generalização da classificação.
- Expansão do Escopo de Análise: A inclusão de outras categorias de URLs maliciosos, como Redirect-URL, Scam-URL e Drive-by Downloads-URL, ampliaria o escopo da pesquisa e forneceria insights mais abrangentes sobre os desafios da classificação em um cenário mais completo.
6. Referências
[1] BB Gupta, K. Yadav, I. Razzak, K. Psannis, A. Castiglione e X. Chang, “Uma nova abordagem para detecção de URLs de phishing usando aprendizado de máquina baseado em léxico em um ambiente de tempo real”, Computer Communications , vol. 175, pp. 47–57, julho de 2021, doi: 10.1016/j.comcom.2021.04.023.
[2] M. Veale e I. Brown, “Cibersegurança”, Internet Policy Review, vol. 9, não. 4, dezembro de 2020, doi: 10.14763/2020.4.1533.
[3] “O que é um URL malicioso e como nos protegemos contra eles?”, 2 de maio de 2023. https:// experteq.com/what-is-a-malicious-url-and-how-do-we- proteja-contra-eles/ (acessado em 18 de maio de 2023).
[4] D. Ali e S. Frimpong, “Inteligência Artificial, Aprendizado de Máquina e Automação de Processos: Fronteira de Conhecimento Existente e Caminho a Seguir para o Setor de Mineração”,
Artificial Intelligence Review, vol. 53, pp. 6025–6042, dezembro de 2020, doi: 10.1007/ s10462-020-09841-6.
[5] S. Johnson, “IA, aprendizado de máquina e ética em cuidados de saúde”, Journal of Legal Medicine, vol. 427–441, outubro de 2019, doi: 10.1080/01947648.2019.1690604.
[6] D. Gong, “Top 6 Machine Learning Algorithms for Classification”, Medium, 12 de julho de 2022. https://towardsdatascience.com/top-machine-learning-algorithms-for- classification-2197870ff501 (acessado em abril de 2022). 07, 2023).
[7] SH Ahammad et al., “Detecção de URL de phishing usando aprendizado de máquina métodos”, Avanços em Software de Engenharia, vol. 173, pág. 103288, novembro de 2022, doi: 10.1016/j.advengsoft.2022.103288.
[8] B. Wardman, D. Clemens, J. Wolnski, P. Inc – San Jose, Estados Unidos e SD-Estados Unidos, “Previsão de ataques de phishing: Uma nova abordagem para prever o aparecimento de sites de phishing”, Cyber-Security and Digital Forensics, p. 142, 2016.
[9] N. Virvilis, A. Mylonas, N. Tsalis e D. Gritzalis, “Security Busters: segurança do navegador da Web versus sites não autorizados”, Computers & Security, vol. 52, pp. 90–105, julho de 2015, doi: 10.1016/j.cose.2015.04.009.
[10] D. Sahoo, C. Liu e SCH Hoi, “Detecção de URL malicioso usando aprendizado de máquina: uma
pesquisa”. arXiv, 21 de agosto de 2019. doi: 10.48550/ arXiv.1701.07179.
[11] “O que é um URL? - Aprenda desenvolvimento web | MDN”, 23 de fevereiro de 2023. https://developer.mozilla.org/en-US/docs/ Learn/Common_questions/Web_mechanics/What_is_a_URL (acessado em 04 de março de 2023).
[12] A. Singh, N. Thakur e A. Sharma, “Uma revisão de algoritmos de aprendizado de máquina supervisionados”, em 2016, 3ª Conferência Internacional sobre Computação para o Desenvolvimento Global Sustentável (INDIACom), março de 2016, pp.[On-line]. Disponível:
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7724478
[13] “Algoritmo de Classificação em Aprendizado de Máquina - Javatpoint,”
www.javatpoint.com. https://www.javatpoint.com/classification-algorithm-in-machine-learning (acessado em 04 de março de 2023).
[14] “Processo de Classificação – uma visão geral | Tópicos ScienceDirect.” https://www.sciencedirect.com/topics/engineering/classification-process (acessado em 05 de março de 2023).
[15] A. Jafar e M. Lee, “Otimização de hiperparâmetros de alta velocidade para modelos ResNet
profundos em reconhecimento de imagem”, Cluster Comput, maio de 2021, doi: 10.1007/ s10586-021-03284-6.
[16] B. Akinremi, “Melhores ferramentas para ajuste de modelo e hiperparâmetros
Optimization”, neptune.ai, 21 de julho de 2022. https://neptune.ai/blog/best-tools-for-model- tuning-and-hyperparameter-optimization (acessado em 12 de março de 2023).
[17] T. Shah, “About Train, Validation and Test Sets in Machine Learning”, Medium, 10 de julho de 2020. https://towardsdatascience.com/train-validation-and-test-sets-72cb40cba9e7 (acessado em março 13, 2023).
[18] AK Baareh, A. Elsayad e M. Al-Dhaifallah, “Reconhecimento de emenda- sequências genéticas de junção usando floresta aleatória e otimização bayesiana”, Multimed Tools Appl, vol. 80, não. 20, pp. 30505–30522, agosto de 2021, doi: 10.1007/s11042-021-10944-7.
[19] M. Aljabri et al., “Uma avaliação de recursos lexicais, de rede e baseados em conteúdo para detectar URLs maliciosos usando aprendizado de máquina e modelos de aprendizado profundo”, Computational Intelligence and Neuroscience, vol. 2022, pp. 14 de agosto de 2022, doi: 10.1155/2022/3241216.
[20] Y. Li, Z. Yang, X. Chen, H. Yuan e W. Liu, “Um modelo de empilhamento usando recursos de URL e HTML para detecção de páginas da web de phishing”, Future Generation Computer Systems, vol. 94, pp. 27–39, maio de 2019, doi: 10.1016/j.future.2018.11.004.
[21] A. Saleem Raja, R. Vinodini e A. Kavitha, “Detecção de URL maliciosa baseada em recursos
lexicais usando técnicas de aprendizado de máquina”, Materials Today: Proceedings, vol. 47, pp. 163–166, janeiro de 2021, doi: 10.1016/j.matpr.2021.04.041.
[22] “Habib_Mrad-Detection URL malicioso usando modelos de ML.” https://kaggle.com/code/habibmrad1983/habib-mrad-detection-malicious-url-using-ml-models (acessado em 07 de abril de 2023).
[23] USD R, A. Patil e Mohana, “Detecção de URL malicioso e Análise de classificação usando modelos de aprendizado de máquina”, na Conferência Internacional sobre Tecnologias Inteligentes de Comunicação de Dados e Internet das Coisas (IDCIoT) de 2023, janeiro de 2023, pp. doi: 10.1109/IDCIoT56793.2023.10053422.
[24] “O que é MATLAB?” https://se.mathworks.com/discovery/what-is- matlab.html (acessado em 05 de abril de 2023).
[25] “Conjunto de dados de URLs maliciosos.” https://www.kaggle.com/datasets/sid321axn/malicious-urls-dataset (acessado em 16 de maio de 2023).
[26] M. Aslani e S. Seipel, “Instância eficiente e ciente dos limites de decisão seleção para máquinas de vetores de suporte”, Information Sciences, vol. 577, pp. 598, out. 2021, doi: 10.1016/j.ins.2021.07.015.
[27] M. Aslani e S. Seipel, “Um método rápido de seleção de instância para máquinas de vetores de suporte na extração de edifícios”, Applied Soft Computing, vol. 97, pág. 106716, dezembro de 2020, doi: 10.1016/j.asoc.2020.106716.
[28] H. Sharma e S. Kumar, “Uma Pesquisa sobre Algoritmos de Árvore de Decisão de Classificação em Mineração de Dados”, International Journal of Science and Research (IJSR), vol. 5, abril de 2016, [On-line]. Disponível: https://www.ijsr.net/archive/v5i4/NOV162954.pdf
[29] A. Adeyemi e A. Mosavi, “Domain Driven Data Mining - Aplicação para Business”, International Journal of Computer Science Issues (fator de impacto: 0,3418), janeiro de 2010, [Online]. Disponível: https://www.researchgate.net/publication/249313178_Domain_Driven_Data_Mining_-_Application_to_Business
[30] MS Alam e ST Vuong, “Classificação de floresta aleatória para detecção Android Malware”, na Conferência Internacional IEEE sobre Computação e Comunicações Verdes de 2013 e Internet das Coisas IEEE e Computação Cibernética, Física e Social IEEE, agosto de 2013, pp. doi: 10.1109/GreenCom-iThings-CPSCom.2013.122.
[31] A. Saini, “Support Vector Machine (SVM): Um guia completo para iniciantes,” Analytics Vidhya, 12 de outubro de 2021. https://www.analyticsvidhya.com/blog/2021/10/support-vector-machinessvm-a-complete-guide-for-beginners/ (acessado em 12 de março de 2023).
[32] P. Nellihela, “What is K-fold Cross Validation?”, Medium, 01 de novembro de 2022. https://towardsdatascience.com/what-is-k-fold-cross-validation-5a7bb241d82f (acessado em maio 22, 2023).
[33] C. Woodun, “Fortinet deve se beneficiar do hack SolarWinds-Microsoft(NASDAQ:FTNT) | Procurando Alpha”, 22 de dezembro de 2020. https://seekingalpha.com/article/4395774-fortinet-should-benefit-from-solarwinds- microsoft-hack, https://seekingalpha.com/article/4395774-fortinet-should-benefit-from-solarwinds-microsoft-hack (acessado em 14 de março de 2023).
Apêndice A. RF e DT em conjunto de dados aleatório

Apêndice B. SVM e KNNs em conjunto de dados aleatório

Apêndice C. RF e DT no conjunto de dados DRLSH
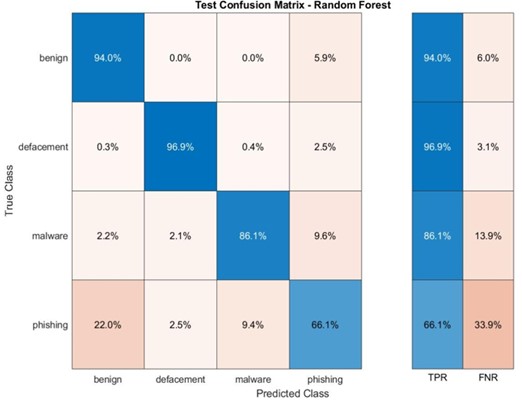
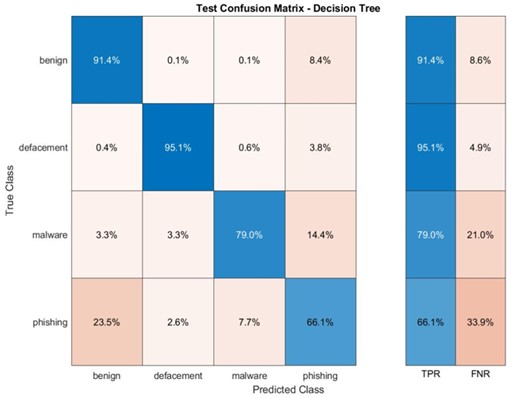
Apêndice D. SVM e KNNs no conjunto de dados DRLSH

Apêndice E. RF e DT no conjunto de dados BPLSH
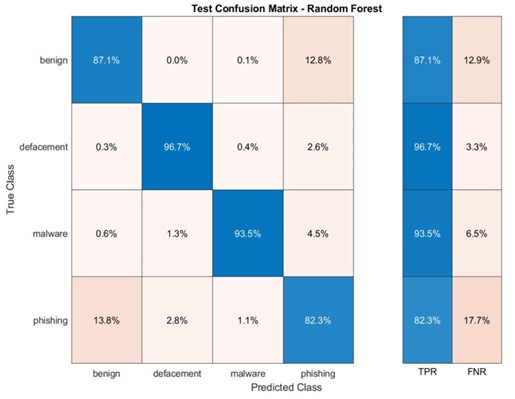

Apêndice F. SVM e KNNs no conjunto de dados BPLSH