


ANÁLISE COMPARATIVA ENTRE BANCO DE DADOS RELACIONAL E NEWSQL EM UM SISTEMA DE PEQUENO PORTE
índice
- 1. RESUMO
- 2. INTRODUÇÃO
- 2.1 JUSTIFICATIVA
- 2.2 OBJETIVOS
- 2.2.1 Objetivo Geral
- 2.2.2 Objetivos Específicos
- 3. FUNDAMENTAÇÃO TEÓRICA
- 3.1 SOFTWARE
- 3.2 BANCO DE DADOS
- 3.2.1 Banco de dados Relacional
- 3.2.2 Relacionamento
- 3.2.3 Cardinalidade de Banco de Dados
- 3.2.4 Linguagem SQL
- 3.2.5 Álgebra e Cálculo Relacional
- 3.2.6 SGBDR MySQL
- 3.2.7 NewSQL
- 3.2.8 VoltDB
- 4. COMPARATIVO TEÓRICO DAS CARACTERÍSTICAS ENTRE BANCOS DE DADOS RELACIONAIS E NEWSQL
- 5. PROCEDIMENTOS METODOLÓGICOS
- 6. RESULTADOS E DISCUSSÃO
- 6.1 SIMULAÇÃO
- 6.1.1 Máquina Virtual 01
- 6.1.2 Máquina Virtual 02
- 6.2 RESULTADOS
- 7. CONSIDERAÇÕES FINAIS
- 8. REFERÊNCIAS
O texto publicado foi encaminhado por um usuário do site por meio do canal colaborativo Monografias. Brasil Escola não se responsabiliza pelo conteúdo do artigo publicado, que é de total responsabilidade do autor . Para acessar os textos produzidos pelo site, acesse: https://www.brasilescola.com.
1. RESUMO
O objetivo deste trabalho de pesquisa é comparar os bancos de dados relacional e NewSQL com apoio de um sistema de pequeno porte, confrontando a teoria com os resultados práticos. Entende-se como banco de dados um ambiente onde são armazenados dados necessários à manutenção e evolução das atividades, independentemente do nível estratégico, tático ou operacional da organização. Um banco de dados relacional é um banco de dados que modela os dados de uma forma que eles sejam percebidos pelo usuário como tabelas, ou mais formalmente relações. Já os bancos de dados NewSQL promovem melhorias de desempenho e escalabilidade, utilizando os benefícios dos bancos de dados relacionais, da linguagem SQL e das propriedades ACID. Tais bancos de dados proporcionam consultas em tempo real e uma maior capacidade de processamento. A metodologia utilizada neste trabalho, foi a pesquisa bibliográfica, pesquisa descritiva e pesquisa aplicada. Para comparar os bancos de dados Relacional e NewSQL optou-se por utilizar o MySQL e VoltDB, respectivamente, e para realizar as inserções e consultas nestes bancos foi desenvolvido um sistema de pequeno porte na linguagem de programação Python. Os resultados apontam que o banco de dados NewSQL, por meio do VoltDB, obteve performance muito superior ao banco de dados MySQL, durante os seus 7.939.332 registros simulados, justificando sua possível adoção.
Palavras-chave: Análise Comparativa. Banco Dados Relacional. NewSQL.
2. INTRODUÇÃO
A internet é parte integrante de um sistema globalizado e cresce em número de usuários, dados, serviços e informações disponíveis na web. (DHILLON 2011)
Nesse cenário, existe uma elevada geração de informações que são projetadas de inúmeras formas, e, considerando a queda dos custos de computadores e dos sistemas de armazenamento aliado ao crescimento exponencial de processamento e armazenamento tornou-se possível a dispersão e distribuição da informação. (MACHADO, 2018)
O armazenamento de dados antes feito em planilhas, arquivos de texto, fitas, disquetes e outros, trazia sérios problemas relacionados a processamento, armazenamento e segurança, e, o surgimento de banco de dados relacionais e seus gerenciadores foram uma importante forma de solução desses problemas. (GONÇALVES, 2014)
Introduzidos nas décadas de 70 e 80 os SGBDRs (Sistemas Gerenciadores de Banco de Dados Relacionais) com seus bancos de dados propriamente ditos, transformaram-se em elementos fundamentais no cotidiano e no desenvolvimento das comunidades modernas. (ELMASRI et al, 2011)
Nos anos atuais é praticamente impossível imaginar organizações que não necessitam armazenar e processar informações, como relacionadas, por exemplo, aos registros de recursos humanos ou, às vezes, utilizando dados como fonte direta de sua renda. (ELMASRI et al, 2011)
Em tempos atuais, por meio do uso da tecnologia, países do mundo inteiro estão combatendo os efeitos da pandemia causada pelo coronavírus SARS-CoV-2, gerador da doença conhecida como COVID-19. A China possui um sistema com mais de 200 milhões de câmeras de vídeo, com software de reconhecimento facial, inclusive já testado em alguns Estados brasileiros. Por meio de filmagens e dados de localização é possível rastrear o movimento de um infectado e tomar providências. (REINALDO FILHO, 2020)
O próprio rastreamento de aparelhos celulares, que está sendo mais um recurso tecnológico útil na luta contra o coronavírus, geram diariamente uma enorme quantidade de dados, de todos os tipos, inclusive de geolocalização armazenados em gigantescos bancos de dados capazes de fornecer informações pontuais e, com isso, indicar por onde as pessoas transitam e em quais períodos. Entende-se, portanto, que os banco de dados são de extrema relevância num cenário em que o mundo se encontra conectado. (REINALDO FILHO, 2020)
Neste aspecto, há de se considerar que a confiabilidade, segurança e disponibilidade, dentre outros atributos existentes nos modelos relacionais contribuem para que os desenvolvedores empreguem menos esforços no banco de dados e mais nas aplicações, fazendo com que este modelo seja considerado o mais utilizado desde sua criação. (DB-ENGINES, 2018)
Importante destacar que para realizar alguns procedimentos como incluir registros ou extrair informações, os bancos de dados relacionais utilizam uma linguagem de consulta estruturada denominada SQL (Structured Query Language), com o objetivo de facilitar a comunicação com o banco de dados. (PUGA; FRANÇA; GOYA, 2014)
No entanto, algumas das características dos sistemas relacionais apresentam-se como desafio às necessidades de aprimoramento em um banco de dados, como problemas de escalabilidade, complexidade operacional, e significativos custos de administração e suporte. (PUGA; FRANÇA; GOYA, 2014)
Como alternativa ao uso dos modelos relacionais surgiu a abordagem NoSQL em 1998, denominação usada para definir um SGBD (Sistema Gerenciador de Banco de Dados) que não utiliza a tradicional linguagem SQL. Com o NoSQL os bancos de dados ganharam mais desempenho e escalabilidade, porém esses benefícios acabam acarretando em perdas de outras propriedades existentes nos SGSBDs relacionais. (PUGA; FRANÇA; GOYA, 2014)
Aproveitando tais deficiências surge uma nova classe de SGBD, assim denominado NewSQL, uma alternativa que promete unir o que há de melhor nas duas abordagens anteriores, oferecendo grande parte das funcionalidades da linguagem SQL com as vantagens das tecnologias NoSQL. (FARAON, 2018)
De acordo com o exposto o problema de pesquisa deste TCC é:
Qual resultado da comparação dos bancos de dados Relacional e NewSQL com apoio de um sistema de pequeno porte confrontando a teoria com os resultados práticos?
Este trabalho de pesquisa está, portanto, organizado da seguinte maneira: na seção 1 consta a introdução; na seção 2 é apresentada a fundamentação teórica, um conjunto dos assuntos que suportam o tema abordado no referido trabalho; a seção 3 apresenta os procedimentos metodológicos com explicações de como a pesquisa foi realizada e qual foi sua proposta; na seção 4, os resultados e discussão, que é a análise realizada, dados coletados e o tratamento desses dados; a seção 5 mostra as considerações finais, em que pese as conclusões apresentadas, e, por fim, as sugestões para trabalhos futuros.
2.1. JUSTIFICATIVA
Justifica-se a importância do tema pela necessidade do mercado em manter e recuperar de forma simples, rápida, íntegra e segura, informações relevantes em diversos segmentos, como por exemplo, controle de vendas, cadastro de clientes, cadastro de funcionários, registradores de temperatura e umidade em áreas industriais, e em inúmeras outras finalidades. Isto é, os dados precisam ser armazenados e recuperados de forma eficaz, tornando-se um processo vital para o bom andamento das operações nas organizações.
Outro fator importante a ser destacado, é a evolução constante e rápida da web, de redes sociais, aplicativos e a proliferação de todos os tipos de sistemas que prestam algum tipo serviço à sociedade, gerando grande massa de dados e intensificando a relação com os usuários, resultando em dados que são trafegados em tempo real, havendo a necessidade de serem analisados e armazenados. Aliado ao exposto, existe uma questão de desempenho e de restauração em alta velocidade, dificultando toda a operação.
Com base na literatura qualificada os autores deste trabalho identificaram que as organizações de Tecnologia da Informação estão a empregar soluções híbridas para atender diferentes demandas de clientes, como por exemplo o uso de um SGBD Relacional como SQL Server, Oracle, MySQL, Postgres e um SGBD NoSQL, podendo-se citar o MongoDB, Redis, Cassandra, entre outros.
Por meio do comparativo prático traçando inclusive um construto teórico entre bancos de dados Relacional e NewSQL pretende-se identificar quais os ganhos ou gargalos que podem ser encontrados em cargas de trabalho, leitura e gravação, em um sistema de pequeno porte, utilizando o suporte dos SGBDs MySQL e VoltDB, respectivamente. Com isso, acredita-se que as organizações poderão tomar decisões fundamentadas para a migração de um SGBD NewSQL ou então pela permanência ou uso híbrido de SGBD.
2.2. OBJETIVOS
2.2.1. Objetivo Geral
Comparar os bancos de dados relacional e NewSQL com apoio de um sistema de pequeno porte confrontando a teoria com os resultados práticos.
Entende os autores deste trabalho que um sistema de pequeno porte se enquadra como um software destinado a atender uma funcionalidade específica e simples com um escopo limitado e escrito em poucas linhas de código. E, neste estudo, criado apenas como um meio de obter a análise e as conclusões necessárias, ou seja, não se trata da atividade fim do referido estudo.
2.2.2. Objetivos Específicos
- Apresentar o que é software;
- Explicar banco de dados Relacional e NewSQL;
- Traçar um comparativo teórico, citando diferenças de comportamento e características entre um banco de dados do tipo relacional e NewSQL;
- Apresentar a correlação entre os resultados práticos identificados no presente estudo em relação a teoria consultada.
3. FUNDAMENTAÇÃO TEÓRICA
3.1. SOFTWARE
Software é um programa de computador com instruções que executadas numa sequência de comandos e operações fornecem saídas com características desejadas, utilizando estruturas de dados que proporcionam aos programas a capacidade de operar informação descritiva na apresentação, tanto impressa como virtual, retratando a operação e a serventia dos programas. (SOMMERVILLE, 2011)
Ainda de acordo com o autor citado, software equivale a programas de computador e documentação composta, desenvolvido para o mercado em geral ou clientes em específico, que devem fornecer funcionalidades requeridas pelo usuário com o máximo de confiança possível, de fácil manutenção e uso, que não cause prejuízos em caso de falhas e que os usuários não consigam prejudicar o sistema.
Um software é mais um item de sistema lógico do que físico, desenvolvido e não fabricado no modo tradicional, cujas atividades dependem do intelecto das pessoas para sua fabricação. (PRESSMAN, 2011; CALVETTI, 2018)
Os custos de um software se concentram no processo de engenharia, tarefa complexa que deve ser gerenciada, planejada e monitorada, incluindo processos e eventos que ocorrem à medida que o software progride, desde conceitos de fundamento até sua disponibilização, efetiva e completa. (PRESSMAN, 2011)
Complementa o autor que a Engenharia de software foi apresentada na conferência da OTAN (Organização do Tratado do Atlântico Norte) em 1969, momento em que o desenvolvimento de softwares passou por vários problemas relacionados a sua construção. Porém, os setores corporativos e governamentais eram e são muito dependentes de sistemas computacionais complexos e confiáveis, e, o aperfeiçoamento dos softwares foi o que permitiu explorar a Internet que são os mais importantes sistemas de informação da humanidade.
A evolução da Internet provocou grandes mudanças na vida das pessoas e nos softwares que eram executados em computadores locais com acesso restrito. Com o advento da Internet vários recursos novos foram adicionados favorecendo para que um novo campo de interação acontecesse, e, pelo fato do seu acesso ser feito por navegadores gerou a necessidade de novos programas com serviços modernos, fazendo com que muitos negócios migrassem para a comunicação web. (SOMMERVILLE, 2011)
Pode-se, portanto, considerar os softwares como ferramentas básicas e até mesmo fundamentais a todo e qualquer processo socioeconômico, sendo essencial e totalmente compreensível a busca pela sua eficiência e eficácia. (CALVETTI, 2018; PRESSMAN, 2011)
3.2. BANCO DE DADOS
Todas as organizações trabalham com informação que precisam ser armazenadas e gerenciadas para atender algum requisito. Estas informações precisam estar disponibilizadas para consulta, armazenadas em sistemas de informação em arquivos digitais ou manuais. (ORACLE, 2020)
Houve um tempo onde o armazenamento de dados era feito em planilhas ou arquivos de texto que eram gravados em computadores, fitas e disquetes. Esse tipo de armazenamento provocava problemas como, duplicidade de dados, inconsistência de informações, arquivos corrompidos e perda de informações.
Não existia uma relação entre as informações, ou seja, não havia ligação entre elas, e com isso pouco se fazia. A solução para este problema foi o surgimento dos bancos de dados e seus gerenciadores, que utilizam técnicas de modelagem de dados em suas implementações, com uma linguagem robusta que permitia um desenvolvimento seguro, confiável, de alto desempenho e processamento. (GONÇALVES, 2014)
Pensando em um sistema computacional, um banco de dados é um conjunto de dados persistentes, utilizado pelos diversos softwares de uma organização, ou seja, um ambiente onde são armazenados dados imprescindíveis à manutenção e evolução das atividades, independente se serve ao nível estratégico, tático ou operacional da organização. (GONÇALVES, 2014)
Um banco de dados é uma coleção organizada de informações tratadas como uma unidade, tendo como objetivo coletar, armazenar e recuperar informações relacionadas para uso por aplicativos de banco de dados. (ORACLE, 2020, p.1)
Os dados são conteúdos existentes na forma bruta que isolados não representam valor significativo, armazenados no banco de dados e que permanecem inertes, significando que permanecerão da mesma forma, a não ser que sejam modificados por algum processo manual ou automatizado. Na Tabela 1, observa-se alguns exemplos de dados, como o CPF, nome, idade e data de nascimento. (HERNANDEZ, 1997)
Tabela 1: Exemplo de Dados
|
CPF |
Nome |
Idade |
Data de Nascimento |
|
05578130638 |
José da Silva |
53 |
17/03/1967 |
Fonte: Dos autores (2020)
Nos sistemas antigos de banco de dados as interfaces eram em linguagem de programação, tornando a implementação de novas consultas cara e demorada, pois novos programas tinham de ser escritos, testados e depurados. Implementados em meados da década de 1960 e continuados nos anos 1970 e 1980, os primeiros bancos de dados eram baseados em três paradigmas principais: hierárquicos, modelo de redes e arquivos invertidos. (HERNANDEZ, 1997)
No modelo hierárquico os dados são estruturados hierarquicamente representando uma árvore invertida, onde uma única tabela irá servir de "Raiz" para a árvore toda, e as outras tabelas serão os "galhos" provenientes da raiz. O usuário precisava estar habituado com a estrutura do banco de dados, para poder acessar o seu conteúdo nele incluso. (HERNANDEZ, 1997)
O modelo de banco de dados em rede é praticamente formado por duas estruturas básicas, os chamados registros e seus conjuntos. Cada registro é formado por um grupo de valores, classificados de acordo com os tipos, os quais permitem descrever a estrutura em que os dados são armazenados. (ALVES, 2013)
A mistura de relacionamentos conceituais com armazenamento e posicionamento físico dos registros no disco, era um dos principais problemas com os sistemas de banco de dados antigos, não conseguindo oferecer abstração de dados e interdependência entre dados e programas. (ELMASRI et al., 2011)
Programas complexos e bem elaborados, chamados de SGBDs, são responsáveis pela construção e manutenção das bases de dados. Inicialmente esses programas deveriam ser suficientemente genéricos permitindo a criação e manutenção de qualquer banco de dados não importando sua aplicação. Os SGBDs devem controlar o acesso aos dados, permitindo somente acessos autorizados, com a responsabilidade de promover mecanismos para backup (cópia de segurança). (GUIMARÃES, 2003)
Os primeiros sistemas relacionais foram desenvolvidos no final da década de 1970, e os SGBDRs foram introduzidos na década de 1980. Até hoje os bancos de dados e sistemas gerenciadores são elementos necessários no dia a dia da sociedade, fazendo com que as pessoas se deparam diariamente com atividades que englobam algum tipo de interação. (ELMASRI et al, 2011)
Com a modelagem de dados foi possível manter os dados em um único lugar, de forma centralizada e organizada. Por meio das regras de padronização de dados, as chamadas Formas Normais, é possível realçar toda estrutura de dados de um sistema, visando a organização, o desempenho e principalmente a flexibilidade e a clareza. Quando se modela um sistema além de criar uma base de dados para o armazenamento, faz-se também uma análise da melhor forma de desenvolvê-la. (GONÇALVES, 2014)
Os dados de uma organização se estendem por muito mais tempo do que os softwares, por isso se faz necessário ter um banco de dados estável, bem-disposto, que tenha uma boa linha de comunicação com várias plataformas de programação e com vários aplicativos diferentes, proporcionando o que há de melhor em segurança e desempenho. (SADALAGE, FOWELER, 2013)
3.2.1. Banco de dados Relacional
No modelo de dados relacional são utilizados conceitos como entidades, atributos e relacionamentos.
Entidade representa um objeto ou conceito do mundo real, como um funcionário ou um projeto do minimundo que é descrito no banco de dados. Um atributo representa alguma propriedade de interesse que descreve melhor uma entidade como nome ou salário do funcionário. Um relacionamento entre duas ou mais entidades representa uma associação entre elas. (ELMASRI et al., 2011, p. 19)
Uma entidade pode ser entendida como um conjunto de coisas, tudo que é percebível ou sensível da realidade representada. Como o objetivo de um modelo entidade relacionamento é modelar de forma abstrata um banco de dados, convém representar somente as coisas ou objetos os quais almeja-se manter as informações. (HEUSER, 2009)
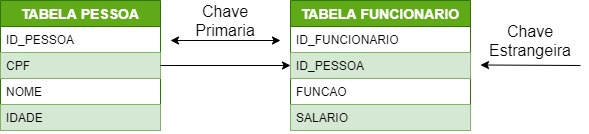
Neste modelo de banco de dados dito como relacional, os dados são armazenados em relações vistas como tabelas, conforme pode ser observado na Figura 1, estruturada por campos que armazenam registros sem se preocupar com a ordenação física, já que cada registro da tabela é identificado por um campo que contém valores únicos, conhecido por Chave Primária, permitindo assim, autonomia na forma de armazenamentos dos dados. (HERNANDEZ, 1997)
Figura 1: Pessoa, apresentação dos elementos.

Fonte: Dos autores (2020)
A tabela é um ajuntamento não ordenado de linhas que na terminologia acadêmica pode estar representado pelo significado de tuplas (ou registros), em que cada linha é composta por uma série de campos que contém um valor de atributo identificado por um nome. (HEUSER, 2009)
O campo é a menor estrutura usada para armazenar dados em um banco de dados relacional, conhecido também como um atributo que pode representar as características de um registro da tabela, onde este campo encontra-se. (HERNANDEZ, 1997)
Um campo com múltiplas partes, passa a ser considerado como o campo que contém mais de um tipo de valor distinto, podendo ser considerado campo multivalorado, contendo um valor concatenado ou que tenha um resultado da expressão matemática chamado de campo calculado. (HERNANDEZ, 1997)
3.2.2. Relacionamento
Desenvolver um sistema para computador independente de seu tamanho ou função, depende de uma dedicação especial em seu propósito e em seu arranjo no banco de dados. Transformar uma ideia conceitual, em algo que possa ser configurado em um computador depende de planejamento prévio e manutenção por parte do desenvolvedor e de quem possa vir a usá-lo. Para isso, foi desenvolvido uma forma padrão para estruturar um banco de dados denominado metamodelo, sendo o mais utilizado o tipo Entidade-Relacionamento. (ALVES, 2013)
Um relacionamento compreende, portanto, uma combinação determinada entre duas entidades (tabelas) de dados. (GILLENSON et al., 2009)
As tabelas organizam os dados e podem ser vinculadas ou relacionadas com base nos dados comuns a cada uma delas. Deste modo, é possível consultar dados usando-se uma ou mais tabelas em uma única consulta. (IBM CLOUD EDUCATION, 2019)
A ligação entre duas tabelas, assim representada pela Figura 2, é o que se denomina relacionamento. Enquanto duas tabelas estiverem ligadas entre si por meio de uma chave primária e/ou estrangeira existe um relacionamento. Pode-se também considerar um relacionamento por meio de uma terceira tabela, conhecida por tabela de conexão. (HERNANDEZ, 1997)
Figura 2: Relacionamento entre entidades.
Fonte: Dos autores (2020)
Relacionamento é algo fundamental em um banco de dados relacional, devendo garantir que nenhuma entidade esteja isolada dentro do contexto. Detectar e interpretar relacionamentos é uma parte valiosa do desenvolvimento de modelagem de dados. (GILLENSON et al., 2009)
No modelo relacional, o autor classifica o relacionamento basicamente em três tipos, que são:
- Relacionamento unário: também conhecido por auto-relacionamento, quando uma entidade se relaciona com ela mesma;
- Relacionamento binário: ocorre entre dois tipos de entidades; e,
- Relacionamento ternário: envolve diretamente três tipos de entidades.
As ligações entre as ocorrências são feitas por intermédio da ligação lógica elaborada por meio de chaves estrangeiras, determinando e mantendo relacionamentos com o uso de ponteiros lógicos. O modelo é fundado em tabelas bidimensionais, onde cada linha representa uma instância única de uma entidade. Essa garantia de unicidade geralmente é feita por chaves primárias que é assegurada em uma coluna ou conjunto de colunas de chaves. (GILLENSON et al., 2009)
Definir chaves seria basicamente determinar relações entre linhas de tabelas de um banco de dados relacional. Pode-se considerar três tipos de chaves, sendo elas: chave primária, chave estrangeira e chave alternativa. (HEUSER, 2009)
Cada chave tem uma finalidade específica em uma tabela e seu tipo determina o seu uso. A chave primária é um campo que identifica um único registro de uma tabela, porém ela se torna a chave estrangeira em outra tabela se esse campo for utilizado para combinar um relacionamento entre ambas as tabelas. Em alguns casos, mais de uma coluna ou combinações de colunas podem servir para distinguir uma linha das demais, passando a ser chave alternativa. (HERNANDEZ, 1997)
Para os casos de relacionamentos binários e unários, cada relacionamento desse pode ser descrito como um-para-um, um-para-muitos ou muitos-para-muitos. Relacionamento ternário existe quando três entidades se relacionam simultaneamente sendo que a cardinalidade, neste caso, refere-se à quantidade de ocorrências de uma entidade em relação ao par das outras entidades, é mais fácil vê-los como conjuntos de relacionamento binários. (GILLENSON et al., 2009)
3.2.3. Cardinalidade de Banco de Dados
No desenvolvimento do um projeto de banco de dados, uma propriedade importante de um relacionamento é a de quantidade de ocorrências que podem estar associadas. Esta propriedade é chamada de cardinalidade. (HEUSER, 2009)
A cardinalidade de um banco de dados representa o relacionamento entre entidades em número de ocorrências, demonstrando um comportamento, podendo ocorrer de um-para-um, um-para-muitos e muitos-para-muitos. Duas tabelas são ligadas quando um campo de compartilhamento detém valores iguais em uma outra tabela. (HERNANDEZ, 1997)
No relacionamento um-para-um entre duas tabelas, conforme representado na Figura 3, acontece quando um único registro da primeira tabela faz ligação a um único registro da segunda tabela, e um único registro da segunda tabela está ligado a um único registro da primeira tabela. (HERNANDEZ, 1997)
Figura 3: Relacionamento (1:1).

Fonte: Dos autores (2020)
O relacionamento um-para-muitos entre duas tabelas, conforme representado na Figura 4, transcorre quando um único registro da tabela está ligado a um ou mais registros da segunda tabela e um único registro da segunda tabela está ligado a um único registro da primeira tabela. (HERNANDEZ, 1997)
Figura 4: Relacionamento (1:N).

Fonte: Dos autores (2020)
O relacionamento muitos-para-muitos entre duas tabelas, conforme ilustrado na Figura 5, deriva quando um único registro da primeira tabela está ligado a um ou mais registros da segunda tabela e um único registro da segunda tabela está ligado a um ou mais registros da primeira tabela. (HERNANDEZ, 1997)
Figura 5: Relacionamento (N:N).

Fonte: Dos autores (2020)
3.2.4. Linguagem SQL
A IBM no ano de 1977, desenvolveu como forma de interface para os sistemas de banco de dados relacionais chamada SEQUEL (Structured English Query Language), Linguagem de Consulta Estruturada, em Inglês, que logo veio a ser chamada apenas de SQL. (PUGA; FRANÇA; GOYA, 2014)
Um banco de dados relacional tem, portanto, o SQL como linguagem de consulta estruturada para manipulação de lógica, com o objetivo de facilitar a conversa com o banco de dados, a fim de recuperar informações desejadas, tornando-se padrão e modelo de como os dados são acessados. (MASLAKOWSKI, 2001)
Em 1986 a ISO (International Organization for Standardization), ou Organização Internacional para Padronização, publicou o padrão de linguagem SQL para banco de dados relacionais, passando por revisões posteriores, com última publicação em 2016 por meio da norma ISO/IEC 9075-2:2016. (PUGA; FRANÇA; GOYA, 2014; MELTON et al, 2016)
Linguagem de consulta estruturada não é uma linguagem de programação, trata-se de um meio de poder se comunicar com o banco de dados relacional para realizar alguns procedimentos, como incluir registros ou extrair informações, classificada como de quarta geração, por ser o mais perto possível da língua humana. (ALVES, 2013)
A SQL oferece uma interface da linguagem declarativa de abstração, relativamente elevado, próximo a linguagem humana, de modo que o usuário apenas mencione qual deve ser o resultado, permitindo o melhoramento real e as decisões sobre como executar a consulta para o SGBD, mesmo que a SQL possua alguns recursos de álgebra relacional, com base em cálculos, tornando-se a linguagem formal mais fácil de se utilizar. (ELMASRI et al., 2011)
A SQL apresenta o conceito de esquema que agrupa tabelas e outros objetos que pertencem a mesma aplicação de banco de dados, como por exemplo, procedimentos (procedures), visões (views), índices, funções (functions), entre outros. (ELMASRI et al., 2011)
A linguagem possui grande segurança no acesso a banco de dados, como por exemplo, comandos de criação de usuários, definição de privilégios, controle por papéis (roles), recursos de criação de visão (view), o qual junta campos de uma ou mais tabelas e permite tratar como conjunto único, evitando que usuários de banco de dados ou por meio de uma aplicação acessem dados sigilosos de uma tabela.
Esses comandos em SQL, conforme demonstrado no Quadro 1 e nos Quadros de 3 a 6, são agrupados em cinco categorias: DCL (Data Control Language - Linguagem de Controle de Dados), DDL (Data Definition Language - Linguagem de Definição de Dados), DML (Data Manipulation Language - Linguagem de Manipulação de Dados), DQL (Data Query Language - Linguagem de Consulta de dados) e DTL (Data Transaction Language - Linguagem de Transação de Dados). (PUGA; FRANÇA; GOYA, 2014)
Quadro 1: Categoria de instruções DDL.
|
DDL
Instruções
|
Fonte: Adaptado de Puga; França; Goya (2014)
Um dos comandos DDL é o CREATE TABLE, usado para criar uma nova entidade, especificando nome, atributos e restrições iniciais, com os atributos recebendo um nome específico e um tipo de dado associado. No Quadro 2, é possível observar alguns tipos de dados em SQL. (ELMASRI et al., 2011, p. 59)
Quadro 2: Tipos de dados SQL
|
Números inteiros |
INTEGER, INT, SMALLINT |
|
Números de ponto flutuante (reais) |
FLOAT, REAL, DOUBLE, PRECISION |
|
Cadeia de caracteres de tamanho fixo |
CHAR(n) |
|
Cadeia de caracteres de tamanho variável |
VARCHAR(n), CLOB |
|
Cadeia de bits de tamanho fixo |
BIT(n) |
|
Cadeia de bits de tamanho variável |
BITVARING(n), BLOB |
|
Booleano |
valores: TRUE, FALSE, UNKNOWN |
|
Data e Hora em cadeia |
DATE, TIME, TIMESTAMP |
Fonte: Adaptado de Elmasri, Navathe (2011).
Mesmo com os diferentes tipos de SGBD é possível por meio da padronização da SQL seguir a mesma nomenclatura e formatos, respeitando as particularidades de cada um, facilitando a migração de instruções, funcionalidades e portabilidade entre as plataformas. (ELMASRI et al., 2011)
Quadro 3: Categoria de instruções DML.
|
DML
Instruções
|
Fonte: Adaptado de Puga; França; Goya (2014)
Quadro 4: Subcategorias de instruções DCL.
|
DCL
Instruções
|
Fonte: Adaptado de Puga; França; Goya (2014)
Quadro 5: Categoria de instruções DTL (ou TCL).
|
DTL (ou TCL)
Instruções
|
Fonte: Adaptado de Puga; França; Goya (2014)
Quadro 6: Categoria de instruções DQL.
|
DQL
Instruções
|
Fonte: Adaptado de Brodsky; Bhot; Chandrashekar (2009)
Ressalta-se que com a linguagem DQL é possível fazer consultas complexas pelo fato dele trazer cláusulas heterogéneas, operadores lógicos, operadores relacionais e funções de agregação, tornando possível servirem de filtros. (SANTANA, 2013)
Além de comandos em SQL, os fabricantes fornecem suas próprias extensões de linguagem que vai além dos recursos suportados pelas implementações do padrão SQL, dando funcionalidades adicionais e gerando diferenças nos recursos inicialmente definidos neste padrão. (GILLENSON et al 2009)
A categoria de classificação dos recursos básicos de SQL, conforme demonstrado nos quadros 7 e 8, conta também com os operadores de comandos que são os símbolos de operadores lógicos e relacionais, utilizados para realizar procedimentos aritméticos e comparações lógicas. (GILLENSON et al 2009)
Quadro 7: Operadores Lógicos.
|
OPERADOR |
EXEMPLO |
|
AND |
condição 1 AND condição 2 |
|
OR |
condição 1 OR condição 2 |
|
NOT |
condição 1 NOT condição 2 |
Fonte: Dos autores (2020)
Quadro 8: Operadores Relacionais.
|
OPERADOR |
DESCRIÇÃO |
EXEMPLO |
RESULTADO |
|
= |
Igual a |
9 = 2 |
FALSE |
|
> |
Maior que |
10 > 7 |
TRUE |
|
< |
Menor que |
3 < 1 |
FALSE |
|
>= |
Maior ou igual a |
8 >= 8 |
TRUE |
|
<= |
Menor ou Igual a |
6 <= 4 |
FALSE |
|
<> ou != |
Diferente |
0 != 5 |
TRUE |
Fonte: Dos autores (2020)
Considerando que um banco de dados relacional pode executar várias transações ao mesmo tempo, ou seja, pode realizar operações como leitura, inserção, exclusão ou atualização de dados, no final de cada transação o banco de dados precisa estar em um estado válido e coerente, devendo satisfazer as restrições do esquema. (FARAON, 2018)
Entende-se por transação um conjunto de instruções SQL, definida como uma unidade lógica e que finaliza com um comando de commit (confirmação da transação) ou rollback (ação de retroceder), apresentando quatro propriedades fundamentais conhecidas como ACID (Atomicidade, Consistência, Isolamento e Durabilidade, do inglês Atomicity, Consistency, Isolation, Durability), assim representadas no Quadro 9. (FARAON, 2018; GILLENSON et al. 2009)
Quadro 9: Características do ACID.
|
Atomicidade |
Em uma operação envolvendo duas ou mais partes de informações distintas, a transação será executada totalmente ou não será executada, representando uma unidade de trabalho completa. |
|
Consistência |
A operação cria um novo estado válido dos dados, ou em caso de falha retorna todos os dados ao seu estado anterior, ou seja, a operação é restabelecida. |
|
Isolamento |
Trata-se de uma operação em andamento, como por exemplo, várias transações lendo e gravando em uma tabela ao mesmo tempo, sem intromissão de nenhuma outra concorrente, deve ser executada sozinha, porque muitas transações são executadas simultaneamente. |
|
Durabilidade |
Dados validados são registados pelo sistema de tal forma que mesmo no caso de uma falha e/ou reinício do sistema, por exemplo, falta de energia ou falha, os dados permanecerão disponíveis em seu estado correto. |
Fonte: Adaptado de Gillenson (2009)
A linguagem SQL é um dos principais motivos para o sucesso dos bancos de dados ao trazer muitas facilidades para migração dos bancos de dados entre sistemas. Outra vantagem de ter essa linguagem é de poder escrever comandos em um determinado SGBD Relacional, que pode acessar dados armazenados em outros sistemas de banco de dados relacionais, sem ter que mudar linguagem utilizada. (ALVES, 2013)
3.2.5. Álgebra e Cálculo Relacional
Álgebra relacional fundamenta-se em um conjunto de operações que pega uma ou duas tabelas como entrada e gera uma nova tabela como resultado. São operações que consistem na teoria dos conjuntos, sempre pensando na tabela. A álgebra relacional demanda sempre na existência de definição, de modo que a ordem em que as operações serão realizadas não importa. (MACHADO, 2014)
As operações fundamentais da álgebra relacional são: selecionar, projetar e renomear, todas consideradas como projeções unárias, enquanto as operações de produto cartesiano, união e diferença de conjuntos, são consideradas como projeções binárias. Há ainda as operações em termos, consideradas fundamentais como interseção de conjuntos, ligação natural, dentre outras. Considera-se, portanto, que a álgebra relacional passa a ser considerada uma linguagem de consulta procedural. (MACHADO, 2014)
A álgebra relacional é um conjunto básico de operações para o modelo relacional, uma sequência de operações que forma uma expressão, das quais os efeitos também serão uma relação que representa um resultado de uma consulta ou a solicitação de recuperação de banco de dados, fornecendo a base formal para operações usadas para implementar e otimizar as consultas dos SGBDRs. (NAVATHE, 2011)
Conhecida como uma parte integral do modelo relacional e suas operações a álgebra relacional pode ser fragmentada em duas partes. A primeira considera um conjunto de operações da teoria dos conjuntos matemáticos que inclui união, intersecção, diferença de conjuntos e produto cartesiano, enquanto que a segunda consiste em operações criadas especificamente para bancos de dados relacionais, como seleção, projeção e junção, por ocorrerem em operações unárias e isoladas. (NAVATHE, 2011)
Operações de seleção formam um subconjunto de linhas em uma relação que satisfaça a necessidade de uma condição de consulta, agindo como filtro que manterá apenas a condição instruída, sendo permitido o uso de operadores lógicos (and, or, not). Para a operação de projeção certas colunas da tabela são selecionadas e outras rejeitadas. (NAVATHE, 2011)
As funções de agregação Junção e União podem sumarizar os dados da tabela, tal e qual o tipo aditivo de operações de Junção serve para combinar linhas relacionadas de duas relações em uma única linha maior, no qual permite processar relacionamentos entre as relações. Para o tipo aditivo de operações de União, ocorre a mescla dos elementos de dois conjuntos de diversas maneiras, porém sendo sempre operações binárias e aplicadas a dois conjuntos de linhas com o mesmo tipo. (NAVATHE, 2011; ALVES 2013)
Enquanto a álgebra explica um conjunto de operações para o modelo relacional, o cálculo relacional demonstra uma notação declarativa de alto nível para a classificação de consultas relacionais. (NAVATHE, 2011)
Cálculo relacional não é procedural e suas expressões de cálculos são chamadas de fórmulas que são definidas recursivamente, iniciando com fórmulas atômicas simples, obtendo tuplas de relação ou efetuando comparações de valores usando conectores lógicos. (RAMAKRISHNAN; GEHRKE, 2016)
O cálculo relacional é, portanto, outra importante linguagem formal para os bancos de dados relacionais, possuindo duas variações. A primeira trata-se do cálculo relacional de linhas (ou tuplas) onde não existe uma descrição de como ou em que ordem avaliar uma consulta, especificando o que deve ser recuperado em vez de como recuperá-lo. Já a outra variação é denominada cálculo relacional de domínios, diferenciando-se da primeira pelos tipos de variáveis existentes, as quais abrangem os valores únicos dos domínios dos atributos, visando formar a relação para o resultado da consulta. (NAVATHE, 2011)
3.2.6. SGBDR MySQL
Dentre todos os SGBDRs existentes no mercado, para efeito de estudo e aplicação, os autores deste trabalho optaram, por afinidade técnica, por usarem o sistema de banco de dados MySQL. É importante salientar que essa escolha também está embasada numa lista que contempla mais de 350 SGBDs ordenados pelos mais populares, publicada mensalmente por DB-Engine (2020), sob responsabilidade da empresa austríaca Solid IT, apresentando o MySQL em 2o lugar, atrás apenas do SGBD Oracle, conforme pode ser observado no Gráfico 1. (DB-ENGINES, 2020)
Gráfico 1: Classificação dos SGBDs - Popularidade das tendências.
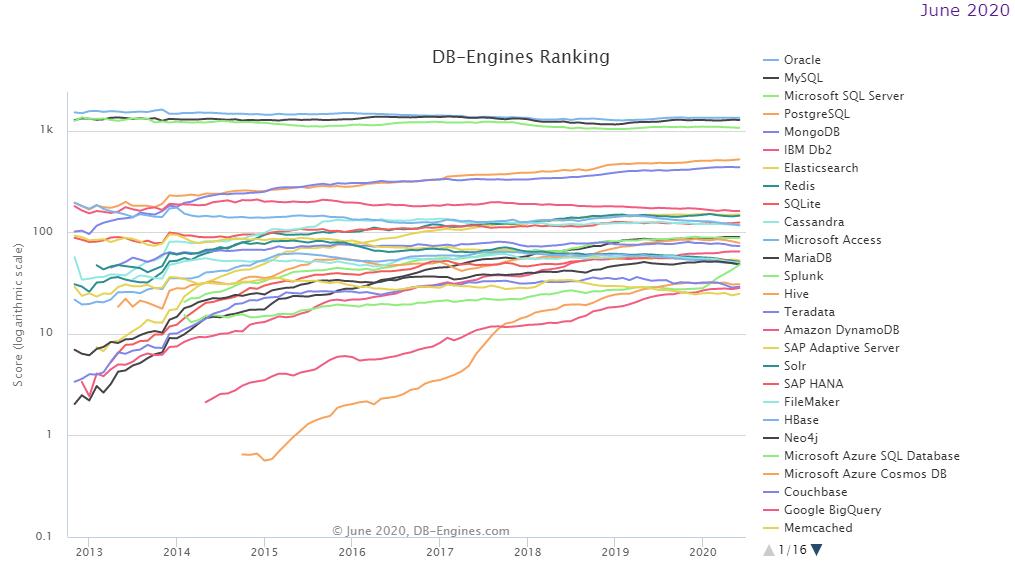
Fonte: DB-Engines (2020)
Cabe destacar que o método do cálculo da popularidade entre os sistemas faz medição em sites, em interesses gerais no sistema, pela frequência de discussões técnicas, número de oferta de emprego, relevância nas redes sociais, dentre outros qualificadores. A lista de sistemas apontados pelo Gráfico 1 mostra que desde 2013 até os dias atuais os bancos de dados Oracle, MySQL e Microsoft SQL Server mantiveram-se nas primeiras colocações.
A primeira versão da base de dados MySQL surgiu da necessidade de uma empresa de consultoria Sueca chamada TcX, fundada em 1985 por Michael Widenius, programador finlandês, que precisava de um servidor de banco de dados que operasse sem exigir plataformas caras de hardware e fosse possível gerar páginas dinâmicas na web. (OLIVEIRA, 2011)
Utilizando-se de utilitários escritos para outro banco de dados existente à época, o mSQL, criado por David Hughes, fundador da Huglhes Tecnologies Pty LTD, a empresa TcX desenvolveu novas APIs para o novo servidor praticamente iguais ao mSQL, sustentando uma performance de funcionamento no uso de memória. Essa união deu origem, posteriormente, à empresa MySQL AB. (LTD, 2017)
Sendo, portanto, baseado no banco de dados mSQL, veloz, confiável e altamente ajustável, o SGBD MySQL começou a fazer frente no mercado pela sua rapidez superando quase todos os concorrentes em praticamente todas as categorias. A popularização do MySQL se deu pelo surgimento do Open Source, termo que se refere ao software, que além de fornecê-lo, oferece também o código fonte. No entanto, o sucesso veio ao distribuir o servidor na Internet, gratuitamente. (MASLAKOWSKI, 2001)
A fabricante de software, computadores e semicondutores Sun Microsystems com sede na Califórnia no Sillicon Valley, EUA, no dia 16 de janeiro de 2008 comprou a empresa MySQL AB, desenvolvedora do MySQL e logo que completou um ano foi anunciado que a Oracle Corporation obteria a Sun Microsystems e todos seus produtos. Contudo, uma investigação da comissão europeia atrasou a compra alegando a formação de monopólio. A solução foi uma integração entre ambas as empresas, em 2010, motivo pelo qual a Sun passou a fazer parte da Oracle, e, desde então, os engenheiros trabalham juntos. (PACIEVITCH, 2011)
Para manipular a linguagem SQL, independente do banco de dados em si, é preciso de um SGBDR, que necessita desse ambiente para utilizar as características e o funcionamento desta linguagem para manipular os dados. Existem vários SGBDRs que oferecem suporte a SQL, porém, não estão ao alcance de todos devido ao alto custo. É nesse critério que o MySQL alude os sistemas mais utilizados no mercado como o Microsoft SQL Server e Oracle, capaz de operar com comandos SQL. (FERRARI, 2007)
No que tange a sua distribuição, o MySQL reúne vários programas e bibliotecas de cliente, ferramentas administrativas e APIs, além de uma ampla variedade de outros programas que são desenvolvidos e disponibilizados por colaboradores e parceiros. (LIMA, 2003)
Sob a administração da empresa Oracle, o MySQL é um SGBD regido e subordinado pela licença GPL, sendo, portanto, Open Source, o que não significa ser gratuito e, portanto, em aplicações que utiliza o MySQL fora desta licença, se faz necessário adquirir a licença comercial. (ORACLE, 2020)
Trata-se o MySQL de um servidor com capacidade de processamento em um único núcleo da CPU (Central Process Unit - Unidade Central de Processamento) ou em um processador com vários núcleos, seguindo o conceito multi-threaded, que presta serviços a vários usuários ao mesmo tempo por meio da criação de vários conjuntos de tarefas a serem executados compartilhando os recursos de um único processo. Suas atividades são realizadas em back-end, ou seja, sem controle do usuário. (DB-ENGINES, 2020)
Para que haja um entendimento melhor da funcionalidade do MySQL, interface e gerenciamento do MySQL, é preciso ter conhecimento prévio da sua estrutura de seus componentes e como é a sua ligação. A construção do gerenciador MySQL foi realizada em várias camadas, conforme descrito por Lima (2003):
- Camada de Aplicação: representa a interface de usuário, que é a maneira com que o servidor MySQL interage com seus usuários. Ressalta-se que esta camada pode ainda ser dividida em três elementos:
- Interface de Consulta: trata-se das instruções DML que é um subconjunto da SQL empregada para selecionar e manipular dados;
- Cliente: são pessoas ou programas que usam a interface do servidor MySQL; e,
- Interface de Administrador: representa os utilitários usados para administração do servidor MySQL.
- Camada Lógica: Constitui uma representação específica de um modelo interno, utilizando as estruturas de banco de dados suportada pelo SGBD escolhido. Descreve como os dados serão armazenados e seus relacionamentos, considerando as seguintes subdivisões:
- Processador de Consultas;
- Gerenciamento de Transações; e,
- Gerenciamento de Recuperação.
- Camada Física: trata-se da terceira e última camada que equivale a forma como o MySQL conserva o armazenamento físico dos dados em arquivos, dicionários, índices, históricos (logs), estatísticas e os demais controles dos recursos de memória. Esta camada é formada por:
- Gerenciador de Recursos;
- Gerenciador de Buffers; e,
- Gerenciador de Armazenamento.
Importante destacar que a arquitetura do MySQL se mostra amplamente competitivo em relação a outros servidores de banco de dados por ser útil para uma gama de objetivos e flexível para trabalhar bem em ambientes exigentes como as aplicações web. (SCHWARTZ et al, 2009)
MySQL possui performance, desempenho, confiabilidade e facilidade de uso, tornando-se uma das escolhas mais comum para bancos de dados de aplicações baseadas na web, usado por gigantes empresariais como Twitter; Facebook; YouTube; Yahoo!; Google, NASA, entre outras. Os desenvolvedores trazem a cada versão desenvolvida do MySQL novas capacidades para melhorar a próxima geração da web, computação em nuvem, computação móvel e aplicações embutidas. (GOMES, 2019)
Outras características do MySQL são a portabilidade, velocidade e escalabilidade, o que vem fazendo com que ele seja adotado e usados por um grande número de desenvolvedores, a contar com seu excelente desempenho na execução de comandos, capacidade de manipulação de tabelas com muito além de quarenta milhões de registros, com fácil e eficiente de privilégios de usuários. O MySQL é mais utilizado no desenvolvimento de aplicações onde a velocidade se torna um fator importante. (ORACLE, 2020)
3.2.7. NewSQL
Para entender o conceito de um banco de dados NewSQL, apesar de não constar no escopo do presente trabalho, é importante compreender a linha de tempo que compete aos bancos de dados do tipo NoSQL.
Em resposta às limitações apresentadas nos modelos relacionais, surgiram os sistemas NoSQL, que alinham alta velocidade operacional e grande flexibilidade no desenvolvimento. Visando buscar uma melhor performance de armazenamento e ou processamento massivo de dados, grandes empresas como Amazon, Facebook, Google desenvolveram sistemas NoSQL. (YEGULALP, 2017)
Para definir um banco de dados não relacional o termo NoSQL foi utilizado pela primeira vez em 1998. Já em 2006 o termo veio à tona quando publicado no artigo BigTable: A Distributed Storage System for Structured Data, publicado pela Google. No ano de 2009, um funcionário do Rackspace reintroduz o termo NoSQL em um evento. (DEVMEDIA, 2012)
A definição foi utilizada para tentar descrever o surgimento de bancos de dados não relacionais, fazendo uma referência ao esquema utilizado para atribuição de nomes a bancos de dados relacionais como MySQL, MS SQL, PostgreSQL e outros. A partir de então, os bancos de dados que não utilizam modelo de relacionamento passaram a ser conhecidos como NoSQL. (DEVMEDIA, 2012)
Nos modelos NoSQL os dados são armazenados livremente sem esquemas, ou seja, qualquer dado pode ser armazenado em qualquer registro. (YEGULALP, 2017)
O NoSQL foi projetado especialmente para arquiteturas distribuídas e com conceito de não seguir padrão e sem a linguagem de consulta SQL, porém com sua utilização desenfreada, vários problemas surgiram, a falta do uso de transações, a própria ausência de consulta SQL e com estrutura complexa sem modelagem, deu-se abertura à nova proposta NewSQL. (GUTIERRY; DEVMEDIA, 2015)
Com o aumento na produção de dados a escalabilidade se torna um desafio para banco de dados relacionais, considerando que quanto maior o tamanho, maior o custo, seja com máquinas ou especialistas. Já com os NoSQL a escalabilidade é mais barata e menos trabalhosa, pois não exigem supercomputadores e são de fácil manutenção. (DEVMEDIA, 2012)
A escalabilidade horizontal que é a capacidade de distribuir os dados, e a carga das operações simples em muitos servidores, é uma das características fundamentais dos sistemas NoSQL. Já na escalabilidade vertical a máquina que é o servidor recebe mais recurso, como por exemplo, memória principal e secundária, processadores, entre outros, conforme representado na Figura 6. (CATTELL, 2018; LIMA, 2018)
Figura 6: Escalabilidades.
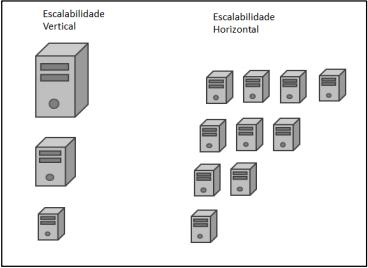
Fonte: Lima (2018)
É um fato que sistemas NoSQL não oferecem o mesmo nível de consistência de dados que os sistemas relacionais SQL. Estes últimos tipicamente sacrificam o desempenho e a escalabilidade das propriedades do ACID em troca de transações mais confiáveis. Os bancos de dados NoSQL descartaram essas garantias do ACID para obter mais velocidade e escalabilidade, permitindo ajustar o sistema ao desempenho ideal, capaz de suportar mais carga de trabalho com baixo custo. (SANTANA, 2019; YEGULALP, 2017)
Muitas organizações usam um banco de dados relacional para armazenar e gerenciar seus dados. Grande parte, desses sistemas são incapazes de lidar com grandes quantidades de dados complexos e atender algumas necessidades. Evidencia-se a utilidade de sistemas que possam fornecer escalabilidade, disponibilidade e alto desempenho, mantendo os recursos importantes dos sistemas relacionais. Ao entender essa necessidade e visando aprimorar os modelos de banco de dados SQL e NoSQL, fornecedores de software desenvolveram um novo modelo de banco de dados, denominado de NewSQL. (PAT RESEARCH, 2020)
O termo NewSQL foi utilizado pela primeira vez em 2011 pelo analista Matthew Aslett, do 451 Group, uma empresa de pesquisa do setor de tecnologia, no seu relatório intitulado “NoSQL, NewSQL and Beyond”. (RIBEIRO, 2013, p.14)
Andrew Pavlo e Matthew Aslett definiram o NewSQL como uma nova classe de sistemas relacionais, com o mesmo desempenho escalável do modelo NoSQL, mas mantendo as garantias ACID nas transações, acreditando em sua expansão gradativa, muito além do que uma questão de marketing. (PAVLO; ASLETT, 2016)
Descrito como sendo um atalho para novas alternativas de sistemas de bases de dados de alta performance e escaláveis, os produtos NewSQL eram conhecidos como ScalableSQL. Ressalta-se que isso acontecia para diferenciar dos produtos do tipo relacional, visto em uma escalabilidade horizontal, mas que não é necessariamente uma característica de todos os produtos. (PAVLO; ASLETT, 2016)
Os NewSQL são, em sua concepção, sistemas de bancos de dados relacionais que combinam cargas de trabalho de leitura e gravação, de processamento de transações online OLTP (Online Transaction Processing), alto desempenho, escalabilidade e disponibilidade. E se diferem em termos de design interno, mas todos são SGBD executando em SQL, usado para gerenciar informações, executar várias transações ao mesmo tempo e modificar o conteúdo do banco de dados. (PAT RESEARCH, 2020)
Em sistemas NewSQL ter a mesma arquitetura não é uma obrigação, depende muito de sua categoria, um sistema pode apresentar características de outras categorias de SGBDs. Esses sistemas variam muito em seu design interno, no entanto existem dois recursos que todos eles suportam, o modelo de dados relacionais e o SQL como interface. (MONIRUZZAMAN, 2014)
A seguir algumas características técnicas do NewSQL segundo CÁ (2018):
- Interação com banco de dados é feita com SQL;
- Suporte ACID para transações;
- Controle de simultaneidade não bloqueável, portanto as leituras em tempo real não entrarão em conflito com as escritas;
- Melhor desempenho por nó oferecido pela arquitetura;
- Arquitetura de escala não compartilhada, capaz de funcionar em um grande número de nós sem sofrerem estrangulamentos.
Quando em um sistema de computadores distribuídos o armazenamento de dados é dividido entre os computadores, cada um desses computadores é considerado um nó. (DEVMEDIA, 2012)
Nos NewSQL os sistemas são projetados e implementados a partir do zero, ou seja, não foram construídos a partir de um outro sistema existente. São fundamentados com arquiteturas distribuídas que atuam em recursos não compartilhados, com o controle de concorrência de vários nós incluindo componentes para suporte, tolerância a falhas por meio de replicação, controle de 23 fluxos e processamento de consulta distribuída. Assim, ao projetar sua arquitetura não há preocupação com detalhes herdados de um sistema legado. A distribuição dos recursos do banco de dados é feita pelo SGBD por intermédio de um mecanismo personalizado. (CÁ, 2018)
Alguns dos produtos existentes no mercado, classificados como SGBD NewSQL são: ClustrixDB, NuoDB, CockroachDB, GemFire XD essencial, Altibase, MemSQL, VoltDB, c-treeACE, Percona TokuDB, Apache Trafodion, TIBCO ActiveSpaces e ActorDB. (PAT RESEARCH, 2020)
3.2.8. VoltDB
Dentre todos os SGBDs do tipo NewSQL existentes no mercado, para efeito de estudo e aplicação, os autores deste trabalho optaram pelo sistema de banco de dados VoltDB. É importante salientar que essa escolha está praticamente embasada numa vasta pesquisa na literatura, já que os bancos do tipo NewSQL, como já remete o nome, são relativamente novos e ainda pouco explorados. Os autores foram em busca dos dez mais utilizados em pesquisa apresentada por DBEngines (2020) remetendo a escolha para este SGBD.
Originalmente um sistema experimental orientado a colunas, projetado para aplicativos de processamento de transações online, o VoltDB é a versão comercial da H-Store. Modernizando vários princípios, como o processamento para dados para maior velocidade, melhorando os resultados das consultas e fornecendo às organizações maior controle operacional. (PAVLO, 2015)
O H-Store, um protótipo acadêmico, era uma prova de conceito de nó único apresentado em 2007 no documento do Very Large Data Bases (VLDB), uma conferência internacional sobre bancos de dados. No ano seguinte, em Brown, MIT e Yale, começaram pesquisas de aperfeiçoamento do H-Store para que fosse um sistema de uso geral e mais completo. Simultaneamente, em um projeto interno e secreto, desenvolvido na Vertica, era lançado o Horizontica. Dois bancos de dados projetados para servir a propósitos distintos. (DATABASE OF DATABASES, 2020)
Alguns meses depois os dois bancos de dados foram combinados, o H-Store contribuindo como back-end, com o mecanismo que coordena as transações, e o Horizontica como front-end, com o planejador de consultas. Os estudos foram adiante e depois de um tempo surgiria o VoltDB. (DATABASE OF DATABASES, 2020)
Os sistemas relacionais estavam perdendo mercado de escalabilidade para os sistemas NoSQL, porém o VoltDB trouxe um novo horizonte para os bancos de dados SQL, garantindo escalabilidade e confiabilidade, em alguns casos conseguindo performance superior aos bancos de dados NoSQL, baseados em chave-valor. (MARIANO, 2010)
O VoltDB pode ser considerado um produto avançado, pois sua arquitetura não se baseia em designs antigos de cerca de 30 anos atrás, quando escalabilidade e performance eram tratadas de uma maneira diferente, pois os bancos de dados não eram projetados para trabalhar com a internet, não eram bancos de dados do tipo web escalável (web-scale). Além disso, o VoltDB contém processamento em memória, distribuição de dados para cada processador da CPU em um cluster, com dados automaticamente replicados em escala, quase linear caso o cluster contenha vários servidores. (MARIANO, 2010)
Entende-se como web escalável (web-scale) a maneira como os data centers e as arquiteturas de software é projetada para incorporar conceitos multidimensionais, como escalabilidade, consistência, tolerância, controle de versão, entre outros critérios. (NUTANIX, 2016)
Na computação o termo cluster define uma arquitetura onde existem vários computadores combinados que trabalham em conjunto. (GOMES, 2015)
Como a principal característica dos modelos MySQL é a clusterização com replicação sob inúmeros servidores, isso garante a confiabilidade e alto dispor dos dados e sua escalabilidade, totalmente compatível com as características ACID do padrão SQL, permitindo que a experiência dos usuários avançados de bancos de dados possa, sem adversidade, fazer transações direto das aplicações. (VOLTDB, 2020)
Preparado para executar milhões de SQL e dezenas de milhares de transações ACID, o VoltDB permite adicionar mais servidores para melhorar ainda mais a eficiência, inclusive dividindo o total de conjunto de dados em partições, conhecido como dados de fragmentos. Essa arquitetura permite que cada partição seja executada de forma independente, sem contenção de bloqueio ou travamento de SGBDRs tradicionais, com tolerância a falhas. Portanto, se um servidor no cluster falhar, o banco de dados contém outra cópia dos dados em servidor separado. (VOLTDB, 2020)
Considera-se o VoltDB um SGBD Relacional com arquitetura não compartilhada, dados dispostos em partições de memória, envio de transações pelos clientes ligados em redes, mantendo uma escalabilidade horizontal, elevando a capacidade do nós e volume em cluster, replicando em vários servidores as partições, garantindo a consistência dos dados e com uma cópia completa em disco. No momento de gravação em disco utiliza mecanismo de replicação assíncrona para recuperação de perdas pela rede, garantindo durabilidade contínua. (STONEBRAKER, 2012)
As principais características gerais do banco de dados VoltDB se resume no seu uso de armazenamento em memória principal, para potencializar o escape de dados, livrando os dispendiosos acessos aos sistemas baseados em disco herdados, no qual se agrega um alto ganho pelo uso da técnica de transformar o estado de um objeto em uma sequência de bytes de acesso a todos os dados, preservando o consumo de tempo das funções de locking, latching e log de transação dos usuais SGBDs. (VOLTDB, 2019)
Para efeito explicativo, latching é um mecanismo utilizado para proteger a integridade dos dados durante as transações, assim gerenciados pelo SGBD. (DBA BRASIL, 2018)
O VoltDB é um banco de dados novo, escalável o suficiente para lidar com facilidade com dados rápidos e confiáveis, tolerante a algumas falhas, sem sacrificar o ACID ou SQL quando alocado na nuvem. Com tecnologia voltada para o desenvolvimento e implementação de aplicativos confiáveis, o VoltDB demonstra eficiência na sua plataforma, oferece os recursos necessários para inserir, organizar, analisar, decidir e exportar os dados rapidamente, apresentando confiabilidade na escalabilidade de desempenho de dados, trabalhando com processos de transações online, projetado para arquiteturas modernas, cujo resultado é um operacional transacional mais rápido. (VOLTDB, 2020)
4. COMPARATIVO TEÓRICO DAS CARACTERÍSTICAS ENTRE BANCOS DE DADOS RELACIONAIS E NEWSQL
Apresenta-se a seguir um comparativo teórico entre as características dos sistemas relacionais e NewSQL, levando-se em conta os seguintes aspectos: escalabilidade, esquema, linguagem padrão, disponibilidade, controle de concorrência, método de particionamento e modelo de dados.
Tanto o banco de dados relacional quanto o banco de dados NewSQL adotam as propriedades ACID que asseguram a atomicidade, consistência, isolabilidade e durabilidade das transações realizadas nos bancos de dados. (FARAON, 2018; GILLENSON et al. 2009; VOLTDB, 2020)
Nos bancos de dados relacionais a escalabilidade é considerada estática no escalonamento vertical, diretamente relacionada com a utilização da CPU, memória e discos. Ressalta-se que por esse motivo, é comum o aumento dos recursos ou a troca total de equipamentos que quase sempre possui um custo alto. Já o modelo de bancos de dados NewSQL possibilita que se realize o escalonamento horizontal, tornando-se muito mais eficaz por poder acrescentar mais nós (servidores) ao sistema, dividindo e replicando as informações. Cabe destacar que os nós acrescentados podem ser inferiores aos já existentes, em termos de tecnologia, e, consequentemente, torna-se mais fácil o escalonamento (FARAON, 2018).
O esquema em ambos os tipos de banco de dados, relacional e NewSQL, é predefinido, fazendo com que os dados inseridos sejam validados na ocasião da inserção. (FARAON, 2018; DOS SANTOS LEMOS, 2014).
A linguagem empregada pelos bancos de dados relacionais e NewSQL para efetuar os comandos é a linguagem SQL, que tem por base a álgebra relacional e o cálculo relacional, entretanto, alguns dos bancos estão admitindo uma linguagem desenvolvida para dados não normalizados (FARAON, 2018; NAVATHE, 2011)
Considerando que a disponibilidade dos bancos de dados está intimamente ligada a escalabilidade dos mesmos, os bancos de dados relacionais não conseguem trabalhar de maneira eficaz nesse quesito, pois em geral a distribuição dos seus dados depende somente de um computador, de modo que a interrupção do serviço tornará o sistema indisponível. Cabe destacar que o banco de dados NewSQL já surgiu com a intenção de resolver esse grande problema que ronda o modelo relacional, apresentando sua capacidade de distribuição dos dados. Neste caso, se um dos nós alocados se tornar indisponível, o sistema funcionará de modo habitual, pois os dados estarão replicados em algum outro nó. (FARAON, 2018; PAT RESEARCH, 2020)
O controle de concorrência existe para que as transações sejam realizadas de maneira que uma transação não interfira em outra. Considerando que os bancos de dados podem ter acessos simultâneos, um SGBD relacional emprega o controle de concorrência baseado em bloqueios, favorecendo para que vários usuários juntos não acessem o mesmo item, empregando o método 2PL, Timestamp e o Otimista. Há de se considerar que no caso dos bancos de dados NewSQL há também o uso do MVCC (Multiversion Concurrency Control) para realizar o controle de concorrência e, conforme o SGBD NewSQL escolhido podem ainda empregar uma combinação do 2PL com o MVCC. (FARAON, 2018)
O banco de dados NewSQL emprega como método de particionamento o sharding, ou seja, um tipo de particionamento horizontal que possibilita dividir o banco de dados em unidades menores (fragmentadas), distribuindo a carga e oferecendo rapidez e facilidade no gerenciamento. Neste modo, o programador não necessita ter a preocupação de qual servidor os dados encontram-se hospedados, pois a solicitação é realizada apenas para um único servidor. No que tange ao banco de dados relacional, o mesmo não tem um método de particionamento que auxilie diretamente, ou seja, para cada situação as instruções precisam ser tratadas. (FARAON, 2018)
Nesse contexto, o modelo de dados dos bancos de dados Relacional e NewSQL, é orientado a linha, mas ressalta-se que o NewSQL pode trabalhar também orientado a colunas em determinadas situações, conforme demonstrado no Quadro 10. (FARAON, 2018)
Quadro 10: Comparativo entre os modelos de bancos de dados.
|
Característica |
Relacional |
NewSQL |
|
Consistência ACID/BASE |
ACID |
ACID |
|
Escalabilidade |
Vertical |
Horizontal |
|
Esquema |
Predefinido |
Predefinido |
|
Linguagem Padrão |
SQL |
SQL |
|
Disponibilidade |
Baixa |
Alta |
|
Controle de concorrência |
2PL/Time Stamp/ Otimista/MVCC |
MVCC/2PL |
|
Método de particionamento |
------- |
Sharding |
|
Modelo de dados |
Orientado a linha |
Orientado a linha / Orientado a coluna |
Fonte: Faraon (2018)
5. PROCEDIMENTOS METODOLÓGICOS
Neste capítulo apresentam-se os procedimentos metodológicos que norteiam esta pesquisa, e, que darão suporte aos objetivos traçados a partir da sua perspectiva.
De acordo com Marconi e Lakatos (2010, p. 65),
Método é o conjunto das atividades sistemáticas e racionais que, com maior segurança e economia, permite alcançar o objetivo- conhecimentos válidos e verdadeiros – traçando o caminho a ser seguido, detectando erros e auxiliando as decisões do cientista.
Portanto, o embasamento teórico e metodológico existe para dar sustentação ao trabalho científico.
5.1. CARACTERIZAÇÃO DA PESQUISA
Vergara (2007), sugere dois critérios para categorização dos tipos de pesquisa, que são quanto aos fins e quanto aos meios utilizados. No que diz respeito aos fins, a presente pesquisa é classificada como descritiva, pois segundo Triviños (2009), permite ao investigador ampliar sua experiência em relação à um determinado problema. Assim, a esta etapa de comparar os bancos de dados Relacional e NewSQL com apoio de um sistema de pequeno porte, a referida pesquisa enquadra-se como descritiva por apresentar a descrição das características de cada um dos bancos de dados Relacional e NewSQL.
Ajusta-se aos padrões de uma pesquisa aplicada, que tem como objetivo dar origem a conhecimentos e contextualizá-los com a realidade social, educacional, científica e tecnológica, de forma a ajudar na solução de problemas específicos. Por meio do comparativo prático sugerido, o estudo irá traçar um construto teórico entre bancos de dados Relacional e NewSQL, identificando quais os ganhos ou gargalos que podem ser encontrados em cargas de trabalho, leitura e gravação, em um sistema de pequeno porte, utilizando o suporte dos SGBDs MySQL e VoltDB, que servirá de guia para as organizações na tomada de decisão quanto a migração de seus dados para um SGBD NewSQL ou a permanência no atual SGBD Relacional, com tecnologia híbrida ou não.
Considerando o exposto, a referida pesquisa é de cunho empírico e enquadra-se como descritiva quanto aos seus fins, pois, conforme explica Gil (2010, p. 43), “[...] tem por objetivo levantar as opiniões, atitudes e crenças de uma população”. Trata-se também de uma pesquisa aplicada, por ser alicerçada pela necessidade de resolver problemas concretos, mais imediatos, objetivando “gerar conhecimentos para aplicação prática, dirigidos à solução de problemas específicos” (SILVA et al 2001, p. 20).
Portanto, para cumprir o objetivo proposto neste TCC, utilizou-se um SGBD Relacional denominado MySQL e um SGBD NewSQL, o VoltDB, como ferramentas de banco de dados, e, para realizar as inserções e consultas nos bancos optou-se por um sistema simples e pequeno desenvolvido na linguagem de programação Python. No Quadro 11 é possível identificar as versões do SGBDs empregados nas simulações.
Quadro 11: Versões dos SGBDs.
|
Modelo |
Versão |
|
Relacional |
MySQL 5.7.3 |
|
NewSQL |
VoltDB 9.3.1 |
Fonte: Dos autores (2020)
A escolha do SGBD MySQL se deu por ser gratuito em algumas versões, e por ser um dos SGBDs relacionais mais populares, possuindo uma vasta documentação, e, pelo fato dos autores do TCC possuírem uma base de conhecimento da ferramenta. Já a escolha do VoltDB é por ser um dos SGBDS mais populares neste modelo, e pelo fato dos autores terem contato com profissionais que já trabalharam, mesmo que superficialmente, com a ferramenta.
E, por fim, a escolha da linguagem de programação Python, que complementa o ferramental de trabalho desse estudo, se deu pela facilidade de codificação, oportunizando a construção de um código robusto, de fácil desenvolvimento e manutenção, e por ser de domínio dos autores.
Embora seja considerada uma linguagem de programação que não contempla um conjunto tão abrangente de pacotes e bibliotecas, como exposto por Matos (2019), entende os autores atender plenamente para o desenvolvimento de um sistema de pequeno porte aqui proposto.
Ambos os SGBDs fornecem ferramentas de comunicação direta, no proposto trabalho empregou-se o MySQL Workbench, ferramenta de interface visual avançada padrão para usuários, e o VoltDB que apresenta uma aplicação nativa de interface que pode ser acessada por um navegador com o endereço local do servidor e configurando a porta de acesso. Com estas ferramentas é possível desenvolver, administrar e visualizar os objetos e os dados que estão no respectivo banco de dados.
Os testes foram todos realizados em um ambiente virtual com sistema operacional Kali Linux de 64 bits em duas máquinas com configurações distintas. Essa escolha se deu pela familiaridade dos autores para com sistemas operacionais de distribuição Linux, os quais oferecem alto desempenho e performance operacional, proporcionando segurança, consistência e flexibilidade de trabalho. Merece destaque também o Linux por ser um sistema operacional gratuito e de código aberto, além de ser altamente recomendado para a configuração de servidores. Somado a esse fator, o SGBD VoltDB só executa em sistemas operacionais Linux e MacOS.
Apesar do VoltDB ser um sistema definido para trabalho em clusters com mais de um nó, os autores deste estudo optaram por delimitar os testes para serem feitos em nó único, por não haver recursos materiais e financeiros para dispor de uma infraestrutura desse porte.
A comunicação e a interação com os bancos de dados se deram pelo software desenvolvido que representa o sistema de pequeno porte, possibilitando a realização de comandos do tipo inserts e selects em ambos os bancos de dados como demonstrado na Figura 7.
O software supracitado apresenta uma tela com duas abas, uma dedicada ao banco de dados MySQL e a outra ao VoltDB. Em cada tela encontra-se:
- Seis campos com tipos de dados diferentes;
- Um campo para digitar a quantidade de registros a serem inseridos no banco;
- Botão para inserir os dados na tabela, insert;
- Botão para realizar busca no banco de dados, select.
Figura 7: Comunicação e interação com os bancos de dados.
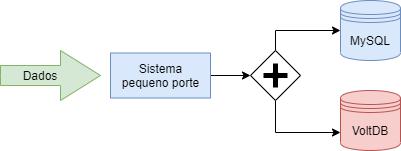
Fonte: Dos autores (2020)
Escolher um SGBD que melhor servirá para um determinado sistema de informação, seja ele qual for, é sempre um desafio para os profissionais da área de TI. Atualmente, devido a imensidade de SGBDs disponíveis, essa tarefa se torna ainda mais complexa. Para uma boa escolha se faz necessário conhecer boa parte dos SGBDs disponíveis, além de definir a sua própria estratégia de dados, analisando seu modelo de negócio. Neste sentido, os autores do presente estudo entendem que os SGBDs selecionados, MySQL e VoltDB, suprem aos objetivos propostos.
Para o alcance dos objetivos, a pesquisa bibliográfica também foi contemplada, por fundamentar-se em trabalhos científicos de autores renomados na área em estudo, sendo estruturada a partir de fontes secundárias que abrange toda a literatura já tornada pública em relação a um determinado assunto. De acordo com Marconi; Lakatos (2010, p. 166), são partes integrantes da pesquisa bibliográfica as “publicações avulsas, boletins, jornais, revistas, livros teses, artigos disponibilizados na internet etc., e, sua finalidade é colocar o pesquisador em contato direto com tudo o que foi escrito sobre determinado tema”.
6. RESULTADOS E DISCUSSÃO
6.1. SIMULAÇÃO
Para manipular dados fictícios, foi criada uma tabela chamada REGISTRO em cada um dos sistemas de banco de dados, MySQL e VoltDB, contendo os atributos NOME, CPF, RG, SEXO, SALÁRIO, NASC (data de nascimento) e ID (identificador). A escolha desses atributos aleatórios justifica-se pela presença de dados do tipo texto, comumente de menor desempenho que os demais, e pela diversidade de tipos, trabalhando também com dados numéricos e data.
No Quadro 12 os autores apresentam as instruções utilizadas para interações com os bancos de dados, podendo-se observar os tipos de dados no comando DDL denominado CREATE TABLE ou ainda no Quadro 14.
Quadro 12: Instrução.
|
Descrição |
Categoria |
SGBD Relacional (MySQL) |
SGBD NewSQL (VoltDB) |
|
Comando para criar tabela |
DDL |
CREATE TABLE REGISTRO ( `ID` int(11) NOT NULL, `NOME` varchar(50) NOT NULL, `CPF` varchar(50) NOT NULL, `RG` varchar(50) NOT NULL, `SEXO` varchar(50) NOT NULL, `SALARIO` float(50) NOT NULL, `NASC` DATE );
PRIMARY KEY: ID |
CREATE TABLE REGISTRO ( ID INT NOT NULL, NOME VARCHAR(50), CPF VARCHAR(50), RG VARCHAR(50), SEXO VARCHAR(50), SALARIO FLOAT, NASC TIMESTAMP );
PRIMARY KEY: ID |
|
Comando para excluir registros da tabela |
DDL |
DROP TABLE `REGISTRO`; |
DROP TABLE REGISTRO; |
|
Comando para inserir dados na tabela |
DML |
INSERT INTO `REGISTRO`(`ID`,`NOME`,`cpf`,`rg`,`SEXO`,`SALARIO, NASC`) VALUES (?, ?, ?, ?, ?, ?, ?); |
INSERT INTO REGISTRO (ID, NOME, CPF, RG, SEXO, SALARIO, NASC) VALUES (?, ?, ?, ?, ?, ?, ?); |
|
Comando para buscar dados da tabela |
DQL |
SELECT * FROM REGISTRO; |
SELECT * FROM REGISTRO; |
Fonte: Dos autores (2020)
O sistema desenvolvido exclusivamente para a simulação apresenta poucas linhas de código e opera a comunicação, realizando duas instruções, o INSERT e o SELECT nos bancos de dados MySQL e VoltDB. O atributo ID não apresenta um campo de edição na tela, pois são gerados automaticamente por funções dos referidos bancos de dados, mantendo assim o mesmo processo de geração de dados, igualitariamente.
Pode-se observar o status do schema e verificar se os dados foram ou não inseridos na tabela REGISTRO do respectivo banco de dados pelo uso das interfaces de administração dos próprios SGBDs já mencionados anteriormente.
As simulações foram realizadas em dois computadores físicos contendo configurações distintas, porém o processamento se deu em máquinas virtuais contemplando as configurações técnicas representadas no Quadro 13. É importante destacar que as simulações realizadas não possuíam qualquer pretensão de comparar o desempenho entre os computadores, apenas a de oferecer uma opção extra de processamento, já que o comparativo era única e exclusivamente entre os SGBDs Relacional e NewSQL.
Quadro 13: Configuração das máquinas virtuais.
|
Descrição |
Máquina Virtual 1 (MV1) |
Máquina Virtual 2 (MV2) |
|
Sistema Operacional |
Linux Kali 2020.2 |
Linux Kali 2020.2 |
|
Arquitetura |
64 bits |
64 bits |
|
Memória RAM |
3 GB |
3 GB |
|
Espaço em disco |
20 GB |
20 GB |
|
Tecnologia do disco |
SSD |
SSD |
|
Processador |
2 cores |
4 cores |
|
SGBD |
MySQL e VoltDB |
MySQL e VoltDB |
Fonte: Dos autores (2020)
Cada simulação foi dividida pela quantidade de registros inseridos nos bancos de dados, valendo destacar que os registros (dados) são exatamente iguais para todas as operações, conforme demonstrado no Quadro 14, observando-se o tempo que cada SGBD consumiu para inserir e, posteriormente, consultar esses registros.
Quadro 14: Dados inseridos na tabela.
|
Descrição |
Dado |
Tipo |
|
ID |
Gerado automaticamente pelo SGBD |
INT |
|
Nome |
João da Silva |
VARCHAR |
|
CPF |
800.551.150-71 |
VARCHAR |
|
RG |
32.562.500-1 |
VARCHAR |
|
Sexo |
M |
VARCHAR |
|
Salário |
2500 |
FLOAT |
|
Data |
28/06/2020 |
DATE, TIMESTAMP |
Fonte: Dos autores (2020)
Para uma visão de comparação mais assertiva o processo de simulação teve exatamente dez ciclos (C1 a C10), onde cada ciclo foi regrado pela quantidade de registros que eram inseridos na tabela REGISTRO dos bancos de dados avaliados. A quantidade projetada em cada ciclo consta representada no Quadro 15.
Quadro 15: Quantidade de registros por ciclo.
|
C1 |
C2 |
C3 |
C4 |
C5 |
C6 |
C7 |
C8 |
C9 |
C10 |
|
1 |
10 |
100 |
500 |
1.000 |
10.000 |
50.000 |
100.000 |
500.000 |
1.000.000 |
Fonte: Dos autores (2020)
Cabe reforçar que as quantidades declaradas em cada ciclo foram utilizadas nos dois SGBDs, MySQL e VoltDB, e nas duas máquinas virtuais (MV1 e MV2). Ressalta-se ainda que para cada ciclo, obedecendo a quantidade de registros informada, foram realizadas três operações de INSERT e três de SELECT, sempre com as tabelas vazias. Cada operação era, portanto, cronometrada, e, os resultados obtidos eram registrados em segundos, como unidade de medida.
Para exemplificar usando o ciclo de 1.000 registros, ao serem executadas três simulações de INSERT num dos bancos de dados, hipoteticamente, caso seu processamento efetivo tivesse consumido na primeira simulação o tempo de 11 segundos, na segunda 9 segundos e na terceira 10 segundos, resultaria na média de 10 segundos de execução. Essa média do tempo é que foi considerada como valor final do referido ciclo, de um determinado tipo de comando (INSERT ou SELECT), num determinado SGBD e máquina virtual (VM1 ou VM2).
6.1.1. Máquina Virtual 01
Considerando as configurações da MV1 já apresentadas no Quadro 13, ao rodar o processo de simulação completo, obteve-se os resultados descritos nas Tabelas 2 e 3, referente a inserção e leitura de dados, respectivamente.
Tabela 2: Tempo de inserção na MV1.
|
Ciclo |
Número de registros |
Tempo MySQL (seg) |
Tempo VoltDB (seg) |
Diferença VoltDB para MySQL (seg) |
|
C1 |
1 |
0,03 |
0,01 |
-0,02 |
|
C2 |
10 |
0,11 |
0,03 |
-0,08 |
|
C3 |
100 |
0,99 |
0,32 |
-0,67 |
|
C4 |
500 |
5,58 |
1,00 |
-4,58 |
|
C5 |
1.000 |
10,39 |
2,30 |
-8,09 |
|
C6 |
10.000 |
67,04 |
14,81 |
-52,23 |
|
C7 |
50.000 |
507,00 |
67,58 |
-439,42 |
|
C8 |
100.000 |
975,55 |
134,09 |
-841,46 |
|
C9 |
500.000 |
5791,40 |
671,40 |
-5120,00 |
|
C10 |
1.000.000 |
13696,43 |
1616,00 |
12080,43 |
Fonte: Dos autores (2020)
Tabela 3: Tempo de consulta na MV1.
|
Ciclo |
Número de registros |
Tempo MySQL (seg) |
Tempo VoltDB (seg) |
Diferença VoltDB para MySQL (seg) |
|
C1 |
1 |
0,40 |
0,001 |
-0,399 |
|
C2 |
10 |
0,56 |
0,011 |
-0,549 |
|
C3 |
100 |
1,13 |
0,98 |
-0,15 |
|
C4 |
500 |
2,39 |
2,38 |
-0,01 |
|
C5 |
1.000 |
4,21 |
4,20 |
-0,01 |
|
C6 |
10.000 |
22,33 |
35,66 |
13,33 |
|
C7 |
50.000 |
121,66 |
120,05 |
-1,61 |
|
C8 |
100.000 |
erro = 0,39 |
erro=33,54 |
não conclusivo |
|
C9 |
500.000 |
erro = 659,00 |
erro=165,00 |
não conclusivo |
|
C10 |
1.000.000 |
erro=1680,00 |
erro=3,69 |
não conclusivo |
Fonte: Dos autores (2020)
A partir do ciclo C8, com processamento de 100.000 registros, não foi possível obter resultados de consultas em ambas as máquinas virtuais, conforme pode ser observado nas Tabelas 3 e 5. Importante destacar que já se esperava essa falha técnica, provocada por limitações de hardware que não suportam grandes consultas de dados, visto que as máquinas virtuais foram preparadas sob computadores domésticos. Essa limitação resulta num ambiente com memória reduzida e baixo poder de processamento quando comparados com computadores do tipo servidor.
6.1.2. Máquina Virtual 02
Considerando as configurações da MV2 já apresentadas no Quadro 13, ao rodar o processo de simulação completo, obteve-se os resultados descritos nas Tabelas 4 e 5, referente a inserção e leitura de dados, respectivamente.
Tabela 4: Tempo de inserção na MV2.
|
Ciclo |
Número de registros |
Tempo MySQL (seg) |
Tempo VoltDB (seg) |
Diferença VoltDB para MySQL (seg) |
|
C1 |
1 |
0,01 |
0,00 |
-0,01 |
|
C2 |
10 |
0,02 |
0,01 |
-0,01 |
|
C3 |
100 |
0,19 |
0,05 |
-0,14 |
|
C4 |
500 |
0,88 |
0,16 |
-0,72 |
|
C5 |
1.000 |
1,80 |
0,35 |
-1,45 |
|
C6 |
10.000 |
17,70 |
2,67 |
-15,03 |
|
C7 |
50.000 |
86,00 |
12,00 |
-74,00 |
|
C8 |
100.000 |
172,00 |
25,00 |
-147,00 |
|
C9 |
500.000 |
862,00 |
120,89 |
-741,11 |
|
C10 |
1.000.000 |
1812,00 |
245,00 |
-1567,00 |
Fonte: Dos autores (2020)
Tabela 5: Tempo de consulta na MV2.
|
Ciclo |
Número de registros |
Tempo MySQL (seg) |
Tempo VoltDB (seg) |
Diferença VoltDB para MySQL (seg) |
|
C1 |
1 |
0,01 |
0,001 |
-0,009 |
|
C2 |
10 |
0,02 |
0,01 |
-0,01 |
|
C3 |
100 |
1,00 |
0,01 |
-0,99 |
|
C4 |
500 |
1,00 |
0,1 |
-0,9 |
|
C5 |
1.000 |
1,00 |
0,1 |
-0,9 |
|
C6 |
10.000 |
4,00 |
0,8 |
-3,2 |
|
C7 |
50.000 |
18,00 |
0,20 |
-17,80 |
|
C8 |
100.000 |
erro = 6,16 |
erro = 6,75 |
não conclusivo |
|
C9 |
500.000 |
erro = 76,00 |
erro =33,00 |
não conclusivo |
|
C10 |
1.000.000 |
erro = 332,00 |
erro =1,00 |
não conclusivo |
Fonte: Dos autores (2020)
6.2. RESULTADOS
Após a execução completa do processo de simulação, verificou-se que ambos os bancos de dados, o Relacional MySQL e o NewSQL VoltDB, suportaram todos os ciclos de cargas para o comando INSERT, e acusaram erro técnico nos mesmos ciclos (C8 a C10) na execução do comando SELECT.
A diferença de desempenho foi se tornando mais expressiva a favor do SGBD NewSQL, VoltDB, durante a inserção de dados, conforme pode ser observado nas Tabelas 2 e 4, e nos Gráficos 2 e 3, à medida que a carga de dados foi aumentando.
Gráfico 2: Tempo de inserção na MV1.
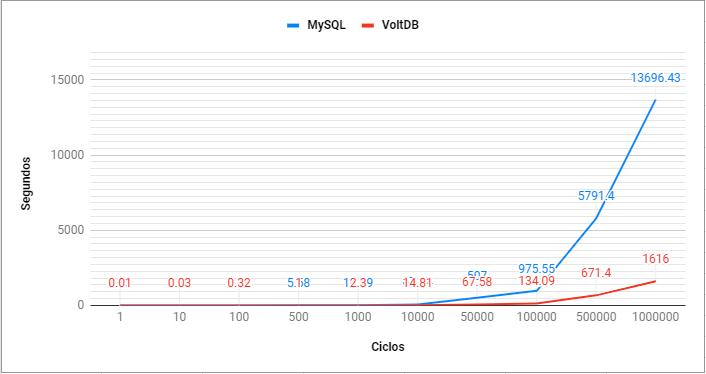
Fonte: Dos autores (2020)
Os valores do eixo X representam os ciclos (C1 a C10) que vão da quantidade de 1 a 1.000.000 de registros, e os valores do eixo Y refletem os segundos que cada ciclo levou para inserir os referidos registros nos bancos de dados. As colunas na cor azul representam o modelo Relacional MySQL, enquanto as colunas na cor vermelho o modelo NewSQL, VoltDB.
Por meio da Tabela 4 e do Gráfico 3, constatou-se na MV2, que nos ciclos C1 a C4 não houveram uma desigualdade significativa para a inserção de dados, com execuções abaixo de 1 segundo em ambos os bancos de dados. Já nos próximos 4 ciclos (C5 a C8), a diferença ainda não é tão representativa, porém é perceptiva, como apresentado no ciclo pertinente a 100.000 registros em que o intervalo de tempo é de pouco menos de 3 minutos. Entretanto, nos últimos 2 ciclos (C9 e C10), em que os números de registros são de 500.000 e 1.000.000, houve uma diferença de tempo bastante significativa e impactante entre os bancos de dados, sendo elas de pouco mais de 12 minutos e acima de 26 minutos, respectivamente.
Gráfico 3: Tempo de inserção na MV2.
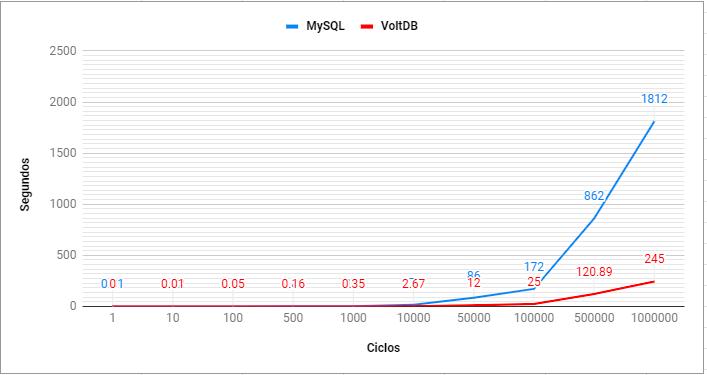
Fonte: Dos autores (2020)
A diferença de tempo no processamento entre as máquinas virtuais MV1 e MV2, se dá pelo número de processadores disponíveis, afetando, evidentemente, o poder de processamento e, consequentemente, nos tempos das simulações. Por outro lado, apesar da diferença entre as máquinas virtuais, as simulações mostraram-se coerentes, sem distorções.
Quadro 16: Comparação de desempenho entre MV1 e MV2 (Insert).
|
Operação INSERT |
|
|
Máquina Virtual |
Desempenho Médio (%) |
|
MV1 |
VoltDB 462,64% mais rápido que MySQL |
|
MV2 |
VoltDB 473,84% mais rápido que MySQL |
Fonte: Dos autores (2020)
Quadro 17: Comparação de desempenho entre MV1 e MV2 (Select).
|
Operação SELECT |
|
|
Máquina Virtual |
Desempenho (%) |
|
MV1 |
VoltDB 6.410,12%* mais rápido que MySQL |
|
MV2 |
VoltDB 3.142,86%* mais rápido que MySQL |
Fonte: Dos autores (2020)
As operações de SELECT apresentaram um resultado bastante intrigante nos ciclos iniciais, mais precisamente nos ciclos C1 e C2. Isto é, se levar em consideração que estes ciclos dizem respeito a consultar apenas 1 e 10 registros da base de dados, e que o SGBD VoltDB mostrou-se extremamente mais eficiente nestes ciclos, ao não considerá-los no cálculo médio de desempenho, para focar em ciclos mais significativos, o percentual mostra-se modificado, conforme Quadro 18.
Quadro 18: Comparação de desempenho a partir do C3 entre MV1 e MV2 (Select).
|
Operação SELECT |
|
|
Máquina Virtual |
Desempenho (%) |
|
MV1 |
VoltDB 4,02% mais lento que MySQL |
|
MV2 |
VoltDB 4.200% mais rápido que MySQL |
Fonte: Dos autores (2020)
Estes resultados demonstram que o número de processadores envolvidos na MV1 e MV2 impactam significativamente quando a operação envolvida é de SELECT, dando indícios de que a característica de escalabilidade torna o SGBD VoltDB mais eficiente.
Os desempenhos obtidos no processo de consulta aos bancos de dados, conforme já mencionados anteriormente, levam em consideração apenas os ciclos C1 a C7, em decorrência da limitação técnica. Os Gráficos 4 e 5 apresentam a relação de tempo para cada ciclo simulado, em cada uma das máquinas virtuais.
Gráfico 4: Tempo de consulta na MV1.
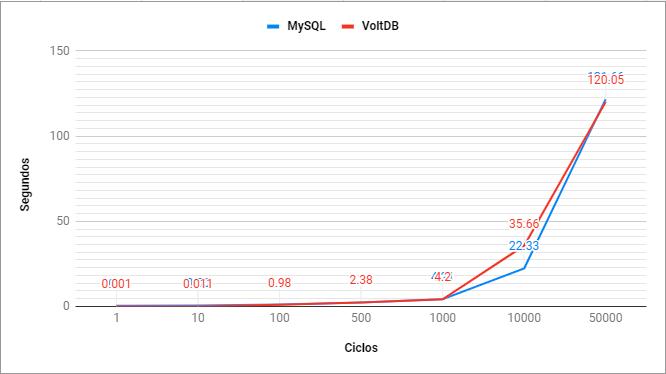
Fonte: Dos autores (2020)
Gráfico 5: Tempo de consulta na MV2.
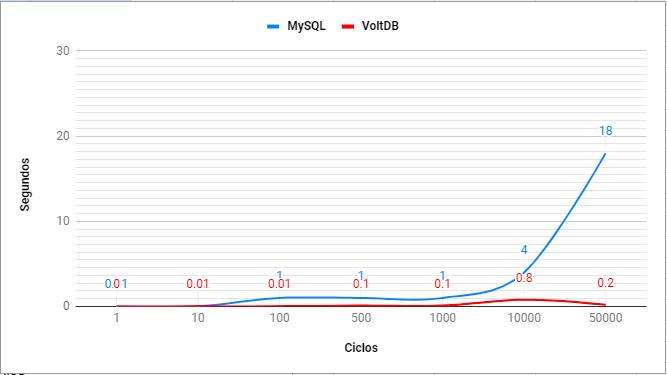
Fonte: Dos autores (2020)
Assim como já relatado, na máquina virtual MV2, é possível perceber o poder de processamento do SGBD VoltDB com o aumento do número de processadores, mantendo em todas as consultas, ciclos C1 a C7, que compreendem de 1 a 50.000 registros, um tempo sempre inferior a 1 segundo.
O resultado da comparação dos bancos de dados Relacional e NewSQL revelou que o SGBD VoltDB consumiu 10,8% do tempo total de todas as respectivas inserções realizadas nos testes, enquanto o SGBD MySQL executou por longos 89,2% do tempo. Esse resultado demonstra que o banco de dados NewSQL foi extremamente mais performático para realizar as inserções em ambos os ambientes criados para as simulações.
Gráfico 6: Total do tempo de inserção por banco de dados.
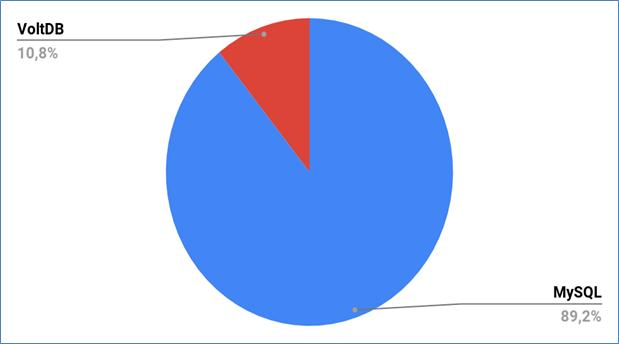
Fonte: Dos autores (2020)
Em comparação semelhante, porém nas operações de consultas, o resultado demonstrou um certo equilíbrio entre os SGBDs Relacional e NewSQL, com o banco de dados VoltDB consumindo 48% do tempo total, enquanto o MySQL executou por 52%, assim representado no Gráfico 7 Apesar da pequena diferença, é importante salientar que os resultados foram limitados por restrições técnicas, não permitindo avaliar de fato o comportamento de ambos os SGBDs em operações de SELECT com grandes volumes de dados.
Gráfico 7: Total do tempo de consulta por banco de dados.
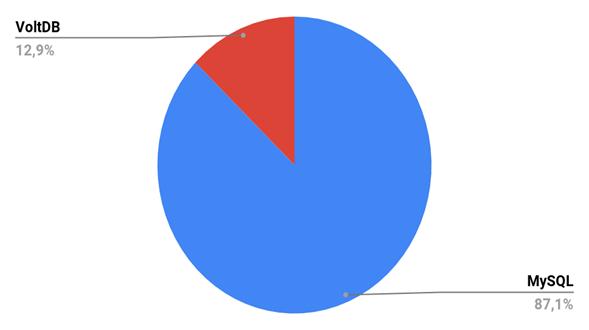
Fonte: Dos autores (2020)
Ainda que limitados tecnicamente, os resultados apontam que, tanto para inserir como para consultar os dados, o SGBD VoltDB mostrou-se mais eficiente que o MySQL.
7. CONSIDERAÇÕES FINAIS
O objetivo deste trabalho de pesquisa foi comparar os bancos de dados relacional e NewSQL com apoio de um sistema de pequeno porte.
Para que o referido objetivo fosse contemplado, realizou-se uma pesquisa na literatura sobre os temas que têm relação direta com o que foi proposto, iniciando por Software que é um programa de computador, com instruções que são executadas numa série de comandos e operações que fornecem saídas com características esperadas.
Verificou-se que NewSQL são sistemas de bancos de dados relacionais que combinam OLTP, alto desempenho, escalabilidade e disponibilidade do NoSQL, conservando as garantias ACID do SGBD Relacional, distinguindo em termos de design interno, mas executando SQL.
No que tange a comparação teórica dos bancos de dados Relacional e NewSQL, considerou-se neste TCC os seguintes critérios:
- Escalabilidade: em que o banco Relacional é vertical e o NewSQL é horizontal, com os sistemas NewSQL projetados para trabalho em clusters, com grande demanda de trabalho;
- Esquema: em que ambos os bancos de dados são predefinidos;
- Linguagem padrão: com ambos os bancos usando a linguagem SQL;
- Disponibilidade: sendo baixa no SGBD Relacional e alta no SGBD NewSQL;
- Controle de concorrência: em que o banco Relacional usa técnicas combinadas de 2PL, Timestamp, Otimista e MVCC, enquanto o SGBD NewSQL adota o MVCC e 2PL.
- Métodos de particionamento: ausente para o banco Relacional e realizado por meio de sharding no banco de dados NewSQL;
- Modelo de dados: com o banco Relacional orientado a linha e o NewSQL orientado a linha e coluna.
Traçando um comparativo entre teoria e prática, as simulações puderam comprovar que os sistemas de banco de dados NewSQL, apesar de ainda ter baixa adesão por parte dos profissionais, são expressivamente mais performáticos em processos de escrita e, relativamente mais ágeis nas leituras, suportando claramente uma grande carga de dados, com alto poder de processamento, principalmente na medida em que se promove um escalonamento horizontal ou vertical.
Com base nos resultados obtidos por meio dos diversos ciclos que fizeram parte do processo de simulação, foi notário que o SGBD NewSQL tem espaço suficiente para disputar por mercado, além de merecer ser avaliado, independente do segmento de atuação da organização.
Entendem os autores deste estudo que todos os objetivos apresentados foram cumpridos, motivo pelo qual dá-se por encerrado este TCC, destacando sua importância como fonte de pesquisa para os profissionais da área, em relação a escolha de bancos de dados. A oportunidade dos autores de colocar em prática os conhecimentos adquiridos durante a realização do Curso Superior de Tecnologia em Análise e Desenvolvimento de Sistemas é outro ponto importante que merece destaque.
7.1. PROPOSTAS PARA TRABALHOS FUTUROS
Nesta seção são definidos os parâmetros e intenção de trabalhos futuros sobre análise comparativa entre banco de dados Relacional e NewSQL em um sistema de pequeno porte.
Cabe ressaltar que o presente trabalho foi desenvolvido em pleno período de pandemia do COVID-19, que vem causando medo generalizado e infectando milhões de pessoas ao redor do mundo, com milhares de mortes.
Considerando o exposto, existe uma lacuna que pode ser explorada e pesquisada em trabalhos futuros, utilizando o experimento já construído e instrumentado neste trabalho de pesquisa. Assim, sugere-se os seguintes trabalhos futuros:
- Realizar uma análise semelhante àquela realizada neste TCC, utilizando um comparativo NewSQL com o emprego de big data, em sistemas de empresas de grande porte;
- Replicar o estudo apresentado neste trabalho em um ambiente de NewSQL em cluster;
- Aplicar os mesmos testes em modelos de banco de dados diferentes para reforçar o entendimento sobre os resultados obtidos nesta pesquisa;
- Complementar a pesquisa fazendo um comparativo de NewSQL com SGBD NoSQL, para afirmar e comprovar as vantagens e diferenças entre os bancos de dados relacionais e não relacionais;
- Realizar simulações com condições restritivas, filtrando por condições específicas, como por exemplo, em coluna do tipo texto e/ou data.
O setor de tecnologia tem oferecido soluções para combater o surto do COVID-19, que variam desde sistemas de detecção da epidemia até o transporte de objetos por drones, em período de quarentena. Portanto, o mundo real se vê cada vez mais conectado com o mundo virtual e nesse aspecto o uso da tecnologia com criatividade revela-se como uma ótima oportunidade de fazer outros comparativos do modelo NewSQL considerados novos, tendo em vista o tempo em que os bancos de dados relacional e NoSQL estão no mercado e quais seriam as vantagens e desvantagens de migrar para um novo modelo.
8. REFERÊNCIAS
AFFILIATES, Oracle And/or Its. Database migration guide. 2014. Disponível em: . Acesso em: 14 junho de 2020.
ALVES, William Pereira. Banco de dados teoria e desenvolvimento. São Paulo: Editora Érica Ltda, 2013. 286 p.
BRODSKY, Alexander; BHOT, Mayur M; CHANDRASHEKAR, Manasa. SIGMOD '09: proceedings of the 2009 ACM SIGMOD International Conference on Management of data June 2009 Pages 1059–1062. Disponível em: . Acesso em: 12 junho de 2020.
CÁ, Lázaro João. Uma abordagem para modelagem de desempenho para sistemas de banco de dados newsql e comparação de modelos gerados com diferentes técnicas de aprendizado de máquina. 2018. 55 f. Dissertação (Mestrado) - Curso de Ciência da Computação, Universidade Estadual do Ceará, Fortaleza – Ceará, 2018. Cap. 2.
CALVETTI, Ewerton Sacco et al. Mensuração do grau de agilidade no processo de desenvolvimento de software: uma abordagem construtivista. Dissertação (Mestrado em Administração) – Universidade Federal de Santa Catarina. 2018.
CATTELL, Rick. Scalable SQL and NoSQL data stores. Disponível em: . Acesso em: 20 abr. de 2020.
DATABASE OF DATABASES (org.). H-Store: History. 2020. Disponível em: . Acesso em: 28 maio de 2020.
DBA BRASIL (Brasil). Locks, blocks e deadlocks – Qual a diferença? 2018. Disponível em: . Acesso em: 29 maio de 2020.
DB-ENGINES. DB-Engines ranking. 2020. Disponível em: . Acesso em: 14 junho de 2020.
DEVMEDIA (Brasil). Introdução aos bancos de dados NoSQL. 2012. Disponível em: . Acesso em: 20 maio de 2020.
_______. O que é um banco de dados distribuído? 2012. Disponível em: . Acesso em: 20 maio de 2020.
DHILLON, G. Violation of safeguards by trusted personnel and understanding related information security concerns. Computers & Security, v. 20, n. 2, p. 165-172, 2001.
DOS SANTOS LEMOS, Pedro Henrique. Uma Análise dos Novos Sistemas de Bancos de Dados Relacionais Escaláveis. 2014. Tese de Doutorado. Universidade Federal do Rio de Janeiro.
ELMASRI, Ramez; NAVATHE, Shamkant B... Sistemas de banco de dados. 6. ed. São Paulo: Pearson Education do Brasil, 2011. 788 p.
FARAON, Renan. Bancos de dados NewSQL: conceitos, ferramentas e comparativo para grandes quantidades de dados. Caxias do Sul, 2018. Trabalho de Conclusão de Curso. Curso Ciências da Computação. Universidade de Caxias do Sul, RS, 2018.
FERRARI, Fabrício Augusto. Crie banco de dados em MySQL. São Paulo: Digerati Books, 2007. 123 p.
GIL, A. C. Como elaborar projetos de pesquisa. 5.ed. São Paulo: Atlas, 2010.
GILLENSON, Mark L. et al. Introdução à gerência de banco de dados. Rio de Janeiro: Gen/ltc, 2009. 295 p.
GOMES, Pedro César Tebaldi. O que é e como funciona um cluster? 2015. Disponível em: . Acesso em: 29 maio de 2020.
______. Quais os principais bancos de dados e quais suas diferenças? 2019. Disponível em: . Acesso em: 19 junho de 2020.
GONÇALVES, Eduardo. SQL: Uma abordagem para banco de dados Oracle. São Paulo: Casa do Código. 2014.
GUIMARÃES, Célio. Fundamentos de Bancos de Dados: Modelagem, Projeto e Linguagem SQL. Editora UNICAMP, 2003, 1º edição.
GUTIERRY; DEVMEDIA. Conheça a geração de banco de dados NoSQL e NewSQL. 2015. Disponível em: . Acesso em: 24 junho de 2020.
HERNANDEZ, Michael J. Aprenda a projetar seu próprio banco de dados. São Paulo: Makron Books do Brasil Editora Ltda., 1997. 411 p.
HEUSER, Carlos Alberto. Projeto de banco de dados. 6. ed. Porto Alegre: Editora Bookman, 2009. 254 p.
HOUSE, Digital. Back-end: o que é, para que serve e como aprender? 2020. Disponível em: . Acesso em: 14 junho de 2020.
H-Store, H-store. Disponível em: . Acesso em: 19 de junho de 2020.
IMB Cloud Education. Relational Databases. Disponível em: . Acesso em: 1, abril de 2020.
LIMA, Adilson da Silva. MySQL Server. Soluções para desenvolvedores e administradores de bancos de dados. São Paulo: Ed. Érica, 2003.
LIMA, Regiane Maciel de Melo. Análise das metodologias de migração de modelos SGBDS relacionais para modelo NoSQL orientado a documentos. 2018. 61 f. Monografia (Especialização) - Curso de Sistemas de Informação, Universidade Federal de Itajubá – Unifei, Itajubá, 2018. Cap. 2.
LTD, Hughes Technologies Pty. MSQL. 2017. Disponível em: . Acesso em: 13 junho de 2020.
MACHADO, Felipe Nery Rodrigues. Big data: o futuro dos dados e aplicações. São Paulo: Saraiva, 2018. 224 p.
MARCONI, M. de A.; LAKATOS, E. M. Fundamentos de metodologia científica. 7. ed. São Paulo: Atlas, 2010.
MARIANO, Pedro. VoltDB: Um novo horizonte para os bancos de dados SQL. 2010. InfoQ. Disponível em: . Acesso em: 23 agosto 2020.
MASLAKOWSKI, Mark. Aprenda em 21 dias MySQL. Rio de Janeiro: Editora Campus Ltda, 2001. 458 p.
MATOS, David. R ou Python para análise de dados?: Python. Python. 2019. Disponível em: . Acesso em: 18 junho de 2020.
MELTON, Jim; DRYDEN, Andrew; BENNETT, Katherine. ISO/IEC 9075-2:2016: Information technology – Database languages – SQL – Part 2: Foundation (SQL/Foundation). ed. 5. 1707 p., 2016.
MONIRUZZAMAN, A. Newsql: towards next-generation scalable rdbms for online transaction processing (oltp) for big data management. arXiv preprint arXiv:1411.7343, 2014
NIEDERAUER, Juliano. Guia de consulta rápida integrando PHP 5 com MySQL. 2. ed. São Paulo: Novatec Editora Ltda, 2008. 104 p.
NUTANIX (Califórnia). Understanding web-scale properties. 2016. Disponível em: . Acesso em: 29 maio de 2020.
OLIVEIRA, Ricardo. MySQL. 2011. Disponível em: . Acesso em: 13 junho de 2020.
ORACLE. Oracle e sun microsystems. 2020. Disponível em: . Acesso em: 13 junho de 2020.
_______. History of MySQL. 2020. Disponível em: . Acesso em 19 junho. de 2020.
_______. What is new in MySQL 5.7. Disponível em: . Acesso em 19 junho de 2020.
_______. Conceitos de banco de dados: Introdução ao banco de dados Oracle. Disponível em: . Acesso em: 15 março de 2020.
______. Manual de Referência do MySQL 8.0. 2020. Disponível em: . Acesso em: 13 junho 2020.
PACIEVITCH, Yuri. MySQL. 2011. Disponível em: . Acesso em: 13 junho de 2020.
PAT RESEARCH (org.). NewSQL: databases. 2020. Disponível em: <https://www.predictiveanalyticstoday.com/newsql-databases>. Acesso em: 20 março de 2020.
PAVLO, Andrew; ASLETT, Matthew. What’s really new with newSQL? 2016. Disponível em: . Acesso em: 06 junho de 2020.
PAVLO, Andy. H-Store: Documentation > Frequently Asked Questions. 2015. Disponível em: . Acesso em: 23 agosto 2020.
PRESSMAN, Roger S. Engenharia de software: uma abordagem profissional. 7. ed. Porto Alegre RS: Amgh Editora Ltda, 2011. 937 p.
PUGA, Sandra; FRANÇA, Edson; GOYA, Milton. Banco de dados implementação em SQL, PL/SQL e Oracle 11g. São Paulo: Pearson Education do Brasil Ltda, 2014. 351 p.
RAFAEL, Bruno. SQL, NoSQL, NewSQL: qual banco de dados usar? 2019. Disponível em: . Acesso em: 24 junho de 2020.
REINALDO FILHO. A Utilização de dados de geolocalização no combate à pandemia do coronavírus - A necessidade de adoção de salvaguardas regulatórias. 2020. Lex Magister. Disponível em: . Acesso em: 15 maio de 2020.
RAMAKRISHNAN, Raghu; GEHRKE, Johannes. Database management systems. 6. ed. Indian: Tata Mcgraw-hill Education India, 2016. 1376 p.
REDHAT.INC, Copyright ©2020. O que é o open source? 2020. Disponível em: . Acesso em: 13 junho de 2020.
RESEARCH, IBM. History of progress. 2020. Disponível em: . Acesso em: 13 junho de 2020.
RIBEIRO, Débora Abigail Carvalho. Bases de dados NewSQL: uma avaliação experimental. Coimbra 2013. 120 f. Licenciatura, Projecto - Curso de Engenharia Informática, Engenharia Informática e de Sistemas, Instituto Superior de Engenharia, 2013.
SADALAGE, Pramod J; FOWLER, Martin. NoSQL Essencial: um guia conciso para o mundo emergente da persistência poliglota. São Paulo: Novatec Editora, 2013. 216 p.
SANTANA, Luiz. Consulta BD: DQL linguagem de consulta de dados. DQL – Linguagem de consulta de dados. 2013. Disponível em: . Acesso em: 14 junho de 2020.
SANTANA, Ítalo. Design de sistemas distribuídos: escalonamento vertical e horizontal. Escalonamento Vertical e Horizontal. 2019. Disponível em: . Acesso em: 23 maio de 2020.
SCHWARTZ, Baron; et al. Alto desempenho em MySQL. Rio de Janeiro: Alta Books, 2009.
SOMMERVILLE, Ian. Engenharia de software. 9. ed. São Paulo: Pearson Education do Brasil, 2014. 529 p.
STONEBRAKER, Michael. New opportunities for New SQL. 2012. Doi:10.1145/2366316.2366319. Disponível em: . Acesso em: 19 abril de 2020.
TRIVIÑOS, A. N. S. Introdução à pesquisa em ciências sociais: a pesquisa qualitativa em educação. São Paulo: Atlas, 2009.
VOLTDB. Using VoltDB in a cluster. 2020. Disponível em: . Acesso em: 14 junho de 2020.
______. Documentation. 2020. Disponível em: . Acesso em: 14 junho 2020.
______. Hadoop database integration. 2020. Disponível em: . Acesso em: 24 junho de 2020.
______. Technical overview. 2019. Disponível em: . Acesso em: 14 maio de 2020.
______. Technical overview. 2020. Disponível em: . Acesso em: 14 junho de 2020.
YEGULALP, Serdar. What is NoSQL? databases for a cloud-scale future. 2017. Disponível em: . Acesso em: 27 maio de 2020.
Publicado por: Murilo Ribeiro
O texto publicado foi encaminhado por um usuário do site por meio do canal colaborativo Monografias. Brasil Escola não se responsabiliza pelo conteúdo do artigo publicado, que é de total responsabilidade do autor . Para acessar os textos produzidos pelo site, acesse: https://www.brasilescola.com.























